- AMD Community
- Support Forums
- PC Processors
- Re: Ryzen linux kernel bug 196683 - Random Soft Lo...
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
PC Processors
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-17-2018
10:38 AM
Ryzen linux kernel bug 196683 - Random Soft Lockup
I have Ryzen 7 1800X, ASUS Prime X370-PRO, running Fedora 26 and 27.
The damn thing has not worked properly since I bought it.
My first CPU was RMA'd, and the replacement does not appear to suffer from the SEGV fault.
However, both the original and the replacement CPU both crash regularly:
* occasionally with streams of "watchdog: BUG: soft lockup" events being logged,
* but mostly the system just stops and I can find no logging that tells me why.
At bugzilla.kernel.org I find bug 196683, where a "workaround" is suggested:
1) kernel configured: CONFIG_RCU_NOCB_CPU=y
2) kernel command-line: rcu-nocbs=0-15
But with kernel 4.14.18-300.fc27 I find the machine has stopped over night (when it is idle), every two or three days.
I have added kernel command-line "processor.max_cstate=5", which may help with the crashes, but (I assume) not with the electricity bill :-(
Does anybody understand what the real fault is ? A "workaround" is all very well, but not entirely satisfactory. It's not as if this is a new device any more.
122 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-24-2018
10:48 AM
Trust me, that's a temporary workaround. It fixed mine for some months then re-appeared. It's the board at fault because the VRMs can't switch from low power to high power fast maybe due to faulty capacitor. It's your wish if you want to replace it or not.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2019
11:56 AM
Can you post some close-up pictures & if possible provide some links to the VRM's specs of the Asus TUF B450 PLUS, board ?
May be the hardware engineers here, can help in doing a comparison!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-08-2019
10:57 AM
Hi. You can find all the details about my Asus motherboard here : https://www.asus.com/Motherboards/TUF-B450-PLUS-GAMING/overview/
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-08-2019
10:46 AM
Interestingly, amdmatt found your reply useful... he also found bthruxton reply to you useful.
samx stated (24-Dec-2018 16:27) that the problem is a motherboard issue.
bthruxton replied (24-Dec-2018 16:44) that the problem had not recurred since setting "Typical Current Idle".
So, amdmatt, can AMD tell us (a) what the root cause of the problem is, and (b) how "Typical Current Idle" fixes or works around it ?
<https://www.amd.com/system/files/TechDocs/55449_Fam_17h_M_00h-0Fh_Rev_Guide.pdf> mentions three MWAIT issues:
1057 MWAIT or MWAITX Instructions May Fail to Correctly Exit From
the Monitor Event Pending State
1059 In Real Mode or Virtual-8086 Mode MWAIT or MWAITX Instructions May
Fail to Correctly Exit From the Monitor Event Pending State
1109 MWAIT Instruction May Hang a Thread
And some people believe that one or more of these may be related to the "freeze-while-idle", and hence that the Linux Kernel setting "idle=nomwait" is the way forward. (I guess we can ignore the Real Mode or Virtual-8086 Mode issues !)
So, for completeness, can AMD tell us (c) which, if any, of these MWAIT issues are addressed by "Typical Current Idle", or whether (d) avoiding MWAIT altogether is the best way to avoid some completely different issue(s) ?
Chris
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-24-2018
09:53 AM
tell me which motherboard do you have?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2019
02:31 PM
I have used ASRock 350M Pro4, A couple 350m based ASUS boards, and a gigabyte 350 based board.
When overclocked @1.4V as I described they all seemed stable.
However when not overclocked the AsRock and Asus periodically hard locked.
I have not tried the gigabyte in a non-overclocked config.
Following recent posts it seems like the lockups happen more with AsRock and Asus I will note that at least Gigabyte uses a higher frequency VRM than Asrock or ASUS which by doing this the VRM will respond faster to load changes maybe this is why more lockups are seen with AsRock esp.
The drawback of higher frequency VRM's is they are less efficient and run hotter at light loads (which for most desktops is 99% of time).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-27-2018
02:18 PM
Dear All,
Today my new discovery indicated that we may be heading wrong direction with regards to CPU core voltage and power states. It has got to be something else.
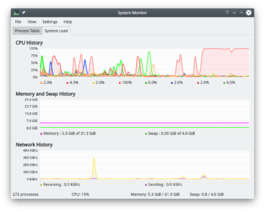
I use the famous linux top command and ksysguard (above imgs) and I sort of AMBUSH the problem awaited to solidly catch a process that frozen.
And my chance came today. I caught my Virtual Machines Backup crontab jobs frozen at the vmware's vmrun suspend command. Info:
My cron jobs put each virtual machines into suspend mode and backup into a harddisk. I got a clue few days ago when I check through my backups, their folder date time stamps suggested that the usual backup jobs which should all be done within 30 mins normally, had on 2 occasions took several hours! There was nothing else wrong beside the long time spent at late night to backup, the data seem quite completely backed up. That means, the lockup or freeze could unfreeze themselves and proceeded to a long delayed completion.
So I ssh into this Ryzen machine at my crontab job hour today, forwarded X and ran ksysguard and top at remote desktop. Yes the cron job frozen and backup was not happening. I also used the linux ps -aux | grep crontab & similar commands, it was confirm that crontab was hanging awaiting for vmrun to suspend the vm, and this command just frozen. It fronzen for almost 2 hours! & later it completed it after this long delay. And my script went ahead further to backup another virtual machine, and after backing up, it is suppose to do vmrun resume but agian, the resume frozen up and took more than 1 hour. After this even my ssh -X session died. I can not reconnect again.
During these hours, I had the top command and ksysguard showing me that other processes and thread were running, ALL my 16 logical (8 physical) CPUs were RUNNING! None of the CPU cores were frozen up in C6 or any other power states, while the thread hang for hours. Because of Hyperthreading, each 2 logical CPUs are from 1 single physical CPU core, and if any core locked up in power state during these hours of lockup, the graphs of 2 logical CPUs must die for each physical CPU to freeze in deep sleep state. If 2 physical cores locked up, than graphs of 2 logical CPUs must die (ZERO % usage).
I am very sure of my observations. It was repeated twice during my AMBUSH mission today. I am very sure of how my scripts work, and how vmrun works, this similar setup and script had worked for more than 10 years, and used on older AMD and Intel machines. This Ryzen is a recent replacement for the retired old server.
I am now not inclined to believe that CPU cores were frozen in deep sleep power states, nor it was Typical Current Idle issue. Not for my Ryzen machine anyway. It has to be something else, RANDOMLY LOCKING UP, and RANDOMLY UNLOCKED THEMSELVES, Affecting process / thread that also appear to be random. I checked the PIDs of these locked up jobs, top said they were in idle state.
While it was locked I went into various /proc folders and files to sniff for clues, did not get anything too useful except to see that they were idle
/proc/[PID]/status
/proc/[PID]/task/[PID]/status
My favorite soft reset systemctl restart sddm had worked many times nearly without fail because I think it flushed out and killed the hanging threads, this command killed X and everything else running on X, which will be quite a big number, and it restarted KDE desktop manager.
I am hoping to get a further breakthrough to find out what caused the thread to LOCK-UP & UNLOCK themselves.
Cheers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-28-2018
01:40 PM
Dear all,
I am now inclined to believe that Linux Kernel 4.18.0-11 gives most of my (remaining) problem because my system most of the time no longer require a reset button on motherboard to get working, like mentioned here, my favorite sudo systemctl restart sddm command via SSH could get the system going again, without a total reboot. My ksysguard graphs shows all CPUs and cores running while backup jobs hanged for hours - the final score on 27-Dec-2018 was a delay over 12hours and the backup crontab script was completed - it resumed itself after hours. This is I think quite different from those of you here who are forced to hit power button or reset button.
I found Kubuntu bug thread and posted there as well, URL is below. May be useful for your reference. The Intel users having similar problems there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2019
03:21 PM
All,
This thread may be discussing one problem that manifests itself in multiple ways or multiple problems, not sure but interesting point of discussion. Here is my take on it:
I do much electronics design and have witnessed first hand how power rail problems can end up resulting in a range of strange issues many that would make one think it is a software issue.
The original start of this thread Linux Kernel Bug 196683 can certainly be explained by a power rail issue causing the CCX lockup and other complete hard locks could simply be the result of both CCX's locking up leaving you with no active CPU.
Could these come out of lockup on there own as uyuy seems to have observed, possibly? or maybe the scheduler eventually moves his process to the CCX that is not locked up?
In fact with the whole ccx and hard lock issue you would think AMD microcode could detect it and just reset (as most processors do) so at least you get a system that is back up and running!
The idle situation is interesting as is the solution that for many has seemed to solve it "Typical idle current BIOS setting". Most VRM's and some PSU's go into another mode when current draw falls enough, they do this to run more efficiently saving power. However it takes some time to go from this low power mode to normal mode and in this time the CPU can be voltage starved. Raising the idle current (through BIOS setting) likely prevents the VRM from falling into this mode meaning that it can rapidly respond when the core(s) enters a higher C State. I will note that the problem does not occur when idle but when a process wakes taking a CPU core(s) out of C6 or lowest allowed C State.
It could also be that the reason Windows users do not see this frequently is that MS has optimized Windows for laptop use and avoid background processes that frequently wake. As this likely only happens on a tiny fraction of a percent of the CPU idle->normal transitions it would stand to reason that this issue is much more rare on Windows. I have also heard that Windows manages C/P state transitions differently from Linux but do not have any details on this.
Note this is a theory but seems to well explain why overclocking or this new BIOS setting create a stable situation and doing nothing results in random instabilities.
The reason this may be daunting for AMD is that the fault does not lie with any one component. The PSU, Mobo
VRM, and CPU and its microcode all have to dance properly for things to work right. This likely also
explains why for some replacing Mobo solved or minimized the problem, for others the PSU, and even differences/tolerances
in the analog part of the Ryzen chip (onboard per core regulator) can make a difference.
I plan to do a test of the current in and voltage out of the VRM when coming out of idle both with the Typical Idle current setting and with the BIOS defaults. I will post these results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2019
11:54 AM
Thanks for the info!, Will wait for the results!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2019
01:29 PM
Dear All,
Some good news and discovery.
My crisis is greatly improved so far after 1st 5 hours running without lockup now. All I did essentially was changing my Linux Kernel from 4.18.0-11-generic to 4.15.0-43-generic
I had previously also tried 4.18.0-13-generic and found it equally bad.
My highest suspicion is 4.18.0-X kernel's thread scheduler is/are buggy with a same bug that would freeze up some threads randomly and up to 12hours long and later randomly unfreeze them. I call that random because I can not find any consistent pattern on how it freeze / unfreeze. These hardly require a hard reset unless it is left frozen for very long time. If I discovered soon enough and gave soft reset by SSH command sudo systemctl restart sddm it will be recovered. It would be gdm instead of sddm if you are in ubuntu instead of kubuntu.
My guess for this difference (between requiring a motherboard reset switch vs soft reset command) is that TOO MANY REPEATED THREAD FROZEN OVER LONGER TIME UNATTENDED. It is a guess only because I cannot afford the time to test and prove that. My faithful logical analysis and derivation is so, because this kernel thread scheduler bug will freeze more & more threads than it unfreeze over longer unattended time, and that critical kernel or driver module threads or ssh or bash itself could have been frozen, hence you have no more chance to soft reset / recover.
I have proven that when only 1 or 2 threads frozen, servers, ssh, bash, and even ksysguard (CPUs usage / load percentage graphs) will still be running and I never found any single CPU core nor logical CPU (hyperthread) completely stuck in ZERO% usage.
When my X.org console freezes, mouse will freeze and CPU usage graph will all freeze, but usually still a good chance if I quickly ssh my favorite reset command sudo systemctl restart sddm it will be recovered. If I wasn't checking and left it frozen for long time, there had been a high chance of it completely not recoverable via ssh command, and reset switch became the only way to get system back rebooted up.
Today, when I checked my CPU Pstate via kernel, it is not running any C6, but I mt BIOS setting neither DISABLED C6 nor use TYPICAL CURRENT IDLE, nor I am using kernel boot idle=nowait , but I think my F4E version BIOS by Gigabyte X470 had DISABLED C6 power state & forced TYPICAL CURRENT IDLE:
~$ cat /sys/devices/system/cpu/cpu*/cpuidle/state*/name
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
C1
C2
POLL
From existing state of stability I am optimistic to expect no further debugging on my system for now.
My proposal for Kubuntu/Ubuntu users is to check kernel version to be other than version 4.18.0-X , and try older 4.15.x 1st, and newer version when they released, if your stability improved with alternate kernels than stay with them and await for improved kernels and try them when they became available.
Thanks & regards
uy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-09-2019
12:17 PM
After about a week since last update, my system which was in trouble is now 99% stable.
It is unfortunate and disappointing and in fact annoying that I had to say 99% instead of 100%, why is annoying is this fault appears to demonstrate some ANALOG nature in a digital computer system. Which is a really rare experience these days, my days with analog electronics already seem like more than a decade ago.
Why I say it is analog is because the following few factors seems to each contribute 20%~30% of the soft lockup problems, and adding/removing each element can increase/decrease your random lockup issues, and even now I still face a slight strange thing or two that I can not explain nor find causes, and never happened to my previous server before, and now I can only RESTART my virtual machine to get rid of these problem. One of it is VPN connection - which works OK when fresh started, and remotely connects OK, but once the remote will manually disconnect and later try to reconnect, it will never be successful, unless I reboot the VPN server.
The elements for me so far are:
- BIOS typical current idle
- Kernel boot parameter idle=nowait
- kernel version
- CPU power state C6
My suspicion now is, it can still improve and stop bugging me if I replaced the system's 2 year old power supply unit which was originally there with the Intel Asus board which retired / got upgraded to Ryzen.
My disappointment is, I am expecting a DIGITAL nature of this bug, that means, lets say CPU POWER STATE C6 had definitely caused these issue, and disabling that MUST 100% removed all these problems, and became 100% stable. Setting back C6 should also get all the old troubles back, and that element should show a digital ZERO or ONE nature to CAUSE and FIX the bug. It is quite annoying to be NOT IN THIS CASE.
Everything in the above list of elements had been found by me to affect soft lockup issue, and which in all theories not very 100% right! No theory so far can fully explain / convince that this bug is solved.
To make it even more shadowy, my currently final issue - the VPN re-connection, some times can be recovered by command init 6 reboot. Some other times however, need me to power off the virtual machine and power on again! But it is a only a VM and it has snapshot to protect data losses, and backup copies. I did these virtual power cycles without fear of screwing it up. I won't do this to the actual computer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-16-2019
02:25 PM
All,
I have commented that I strongly believe that "most" of the strange behavior noted in this thread is the result of power issues to the CPU core(s) I have connected a scope and have some plots but as it appears there is no way to post them here?? I will put them on another web site soon and provide link.
Not sure they tell much as they are taken from a system that to date I have not been able to get to freeze regardless of the Idle Current Setting.
What I have is put together a small test program that cycles between being idle (sleeping for 5-10sec) and quickly waking N (4-64) threads doing a complex workload (a silly calculation) that uses AVX and thereby should get each core up to near Max power consumption. When running this I see on a scope the Vcore voltage going from very low (<0.4V, I think just charge left in caps) to as high as 1.5V on the test system. But have not had a freeze on this system or another Ryzen system I tried.
Am curious if anyone out there who has had system freezes can also get them running this and if they are more/less frequent?? Also do they only happen if Idle Current setting a default or also when Typical Idle Current Set.
Below is the source code for this program just copy and paste into an editor, save it as waketest.c and compile with:
gcc -g -mtune=native -mavx -ftree-vectorize -O3 -fopt-info-vec waketest.c -o waketest -l pthread
To run ./waketest N ; where N is the number of Threads on your Ryzen CPU for 1700+ this should be 16
--------------------------------- Start of waketest.c -----------------------------
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h> /* Semaphores are not part of Pthreads */
#include <unistd.h>
const int MAX_THREADS = 256;
const int MSG_MAX = 100;
/* Global variables: accessible to all threads */
int thread_count;
char** messages;
sem_t semaphores[256];
unsigned int sum[256];
unsigned int total;
void Usage(char* prog_name);
void *ProcFull(void* id); /* Thread function */
/*--------------------------------------------------------------------*/
int main(int argc, char* argv[]) {
long thread;
pthread_t thread_handles[256];
int testnum;
if (argc != 2) Usage(argv[0]);
thread_count = strtol(argv[1], NULL, 10);
if (thread_count <= 0 || thread_count > MAX_THREADS) Usage(argv[0]);
for (testnum=0;testnum<1000;testnum++) {
printf("\nWake up test interation %d\n",testnum);
for (thread = 0; thread < thread_count; thread++) {
// messages[thread] = NULL;
/* Initialize all semaphores to 0 -- i.e., locked */
sem_init(&semaphores[thread], 0, 0);
}
for (thread = 0; thread < thread_count; thread++)
pthread_create(&thread_handles[thread], (pthread_attr_t*) NULL,
ProcFull, (void*) thread);
int sleeptime=5+rand()%5;
printf("Sleeping for %d\n",sleeptime);
sleep(sleeptime);
// wake up N threads very quickly going from idle to near max in less than 1us
for (thread = 0; thread < thread_count; thread++) {
sem_post(&semaphores[thread]); /* let thread go */
}
printf("Woke up all threads!\n");
// wait for all threads to complete
for (thread = 0; thread < thread_count; thread++) {
pthread_join(thread_handles[thread], NULL);
}
total=0;
for (thread = 0; thread < thread_count; thread++) {
sem_destroy(&semaphores[thread]);
total+=sum[thread];
}
// display silly total
printf("All Threads Have Ended Total=%u\n",total);
}
return 0;
} /* main */
/*--------------------------------------------------------------------
* Function: Usage
* Purpose: Print command line for function and terminate
* In arg: prog_name
*/
void Usage(char* prog_name) {
fprintf(stderr, "usage: %s <number of threads>\n", prog_name);
exit(0);
} /* Usage */
/*-------------------------------------------------------------------
* Function: Send_msg
* Purpose: Create a message and ``send'' it by copying it
* into the global messages array. Receive a message
* and print it.
* In arg: rank
* Global in: thread_count
* Global in/out: messages, semaphores
* Return val: Ignored
* Note: The my_msg buffer is freed in main
*/
// function with silly loop that will get vectorized SSE2 to Max out CPU core
void *ProcFull(void* id) {
long tid = (long) id;
int i,n;
// these arrays should fit in L1$
unsigned int a[256] __attribute__((aligned(16)));
unsigned int b[256] __attribute__((aligned(16)));
unsigned int c[256] __attribute__((aligned(16)));
unsigned int d[256] __attribute__((aligned(16)));
unsigned int res[256] __attribute__((aligned(16)));
for (i=0;i<256;i++) {
a=rand()%1024;
b=i*3+7;
c=i*7+819234;
d=i*62134+66;
res=rand()%256;
}
sem_wait(&semaphores[tid]); /* Wait for our semaphore to be unlocked */
// printf("Thread %ld\n", tid);
for (i=0;i<0x1000000;i++) {
for (n=0;n<256;n++) {
res
a
}
}
sum[tid]=0;
for (i=0;i<256;i++) {
sum[tid]+=res;
}
return NULL;
} /* Send_msg */
-------------------------------------- End of waketest.c -------------------------------
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2019
03:47 PM
Well Done!
I may want to test that after I am freed from burdens of several projects. Already have not used my scope for about a decade shipped to warehouse, and don't think it will still work again. May use a digital meter.
Coincidentally I replaced the troubled system's power supply unit from a Corsair RM650 (3yrs old approx) previously used with Intel board, to a 750W Seasonnic Focus FM-750W. I am curious of this would make any difference. So far it is not giving me issue in the last 10hr. In several days I will update if my last chunk of instability is now gone or not. If it became perfect, I will begin to reverse away the other measures one by one for testing. i.e. the Linux kernel boot up parameter (idle=nowait); kernel version; BIOS version; BIOS settings (typical current idle) & C6 power state enable/disable.
As mentioned in my as post, I am annoyed by the issue exhibiting ANALOG NATURE of FAULT in a digital computer, hence the factors each contributed a certain percentage of instability. And ANALOG NATURE points some how towards POWER SUPPLY voltage stability. That is why I upgraded power supply today.
The guy from the shop who sold me the power supply unit today was shocked to learn from me about this Ryzen stability issue. He had been selling Ryzens mostly on Microsoft OS from since AMD made Ryzen available to market, he had not come across this issue. I emailed him the URL to this forum thread.
So far for stability improvement after new power supply I notice a notorious trouble which was quite consistent is gone tonight! Which is a VPN re-connection trouble - this VPN worked fine with Intel, and started to have re-connection issue after changing to Ryzen. It will connect after resetting VPN server. And after deliberate disconnection, it was very hard to get successful re-connection. After changed power supply unit, it seemed to re-connect more easily, almost same as when It was Intel.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2019
08:02 PM
Uyuy,
It sounds like you have experienced just about every problem I have heard reported.
Your point about problems being deterministic is well taken but remember that although the flow of software is mostly deterministic the timing of when things happen is not and many hidden software problems come from timing issues esp in modern multi-threaded programs.
The only issue I have had that is Ryzen specific is these dam random hard locks (in my case) on every Ryzen system to date that is not running with the CPU voltage (VRM) set at a fixed 1.40V in the BIOS and over clocking enabled (which should disable the onboard voltage regulation in the Ryzen chip). These hard locks though on most systems have been rare (occurring less than once a month) on average.
The problems you note seem to be occuring quite often and I have not seen any frequent issues.
I will say though on PSU subject it does seem to matter: I put together a threadripper (16 core system) about 6 months ago. Originally I had a lame 650W supply in it and was seeing hard locks about twice a week and not just while idle. I switched after about 2 months to a much better 850W supply and have not had any hard locks (did have two desktop freezes due to AMDGPU) but was able to ssh in and reboot so I know it was not a hard lock.
Power issues can cause other problems for instance many years ago a flaky 3.3V rail caused strange networking problems. So with power problems different people may see different things happen usually appearing as random instabilities.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2019
05:16 AM
Hi Skull,
I have a verity of problems but nearly never got the WORST which I had read here and elsewhere, which is DEAD-LOCK-UP that will require motherboard reset button or power button to unlock. Almost 95% of the freeze are unlocked by my favorite Kubuntu SSH root command systemctl restart sddm . Doing this disrupts my server's VMs, so I hate this. In some rare cases I lost even SSH.
Main trend of my lockups are proven by the kubuntu's ksysguard (see Picture URL below) and linux top command that none of my logical nor physical CPU core really stayed at 0% ussage - they are all still alive! But some threads just got FROZEN!


In very rare occasions - happens if system is left unattended for long hours - I will even lost SSH, I think this is due to more and more idle tasks got frozen. I need to hit the motherboard / CPU casing reset button.
I suspect it was some bad kernel scheduler issues that frozen some of my NON-IDLE threads - actually nightly backup which is I/O & memory & CPU intensive. This was version 4.18.0-X kernel and after changing the kernel the nightly backup threads don't freeze any more - so I concluded that this part at least can not be blamed on Ryzen CPU.
An update to my system stability days after changing power supply unit to 750 watt, I say there is not very significant improvement. The existing (only) issue of re-connection difficulties for VPN server, only improved slightly, not totally gone. The newest discoveries in this issue suggest that it is not so likely to be caused by Ryzen, I need a week more to further discover.
My question to SKULL is HOW would I find the right measurement points on motherboards for VRM output? I don't have the markings on motherboard, so best chance is only using multi-meter to probe round surface-mounted capacitors and GUESS-WORK. And further I had read somewhere that Ryzen (at least some) have own V-core regulators ON-CHIP??
What do you all think when threads are frozen (not responsive) and yet CPUs are busy working on some other threads? It can not be considered as CPU core locked up right? If the ksysguard CPU usage graphs showed NONE of CPUs are stuck @ ZERO%...
Consider this too: If some CPU cores were frozen in e.g. C6 power state, wouldn't the threads get assigned to other CPUs and continued to work? I mean in this scenario system just slow down from say an 8 core (HT to 16 threads) CPU drop 1st to 7 core (14 threads) then may worsen down to 6/5/4/3/2/1 core? And finally DEAD @ ZERO core?
In my own case I am not see the above scenario at all! I am seeing all my 16 logical (8 physical) cores alive. Just some threads randomly freezes. And some of the freezes will unfreeze itself - this is the case in my nightly backup crontab job - it delayed beyond 12 hours and got COMPLETED.
I had not seen any feedback after posting here, regarding weather gdm (for ubuntu) or sddm (kubuntu) systemctl restart gdm or systemctl restart sddm are found helpful to unlock frozen system by any other users?? Pse post if you found this useful. Otherwise, I am assuming that your systems all locked up until SSH console are all dead??
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2019
01:41 PM
The waketest is interesting, but I have my doubts about it...
My experience of the "freeze-while-idle" is on a machine which overnight is doing next to nothing, and when it did freeze I would see absolutely nothing in the log after some essentially random time in the morning. The machine did not freeze every night. Apart from cron jobs, the machine would be woken up fairly regularly by spurious ssh login attempts from the outside world (background level attempts to break into the system). The longest period when nothing was logged was generally 7 to 10 minutes. I assume that in those periods the machine was, indeed, completely idle.
Note that in my experience the machine was not heavily loaded when it did wake up. Which is not what your test sets out to do.
Further, your test is only going to sleep for 5 seconds. I don't know how long it takes for a given Linux Kernel to send the CPU into the deepest of deep sleeps, but I wonder if 5 seconds is long enough ? I note that you find that's long enough for the voltage to drop right down to 0.4V, which sounds like deep sleep, though I note also that you have not managed to trigger a freeze while running the test.
-------------------------------------------------------------
Of course, I assume Mr AMD knows what the problem is, so we are all wasting our time trying to work it out :-(
My feeling is that most of the issues that uyuy is reporting are *not* related to the problem which "Typical Current Idle" addresses. Indeed, I suspect that a variety of "lockups", nothing to do with the CPU, are being wrongly attributed to a suspected bug in Ryzen CPUs.
amdmatt are you there ? I suggest that a little openness about the bug addressed by "Typical Current Idle" would be better PR ! Silence is not only alienating your customers, but also causing the Ryzen CPU to be blamed for "lockups" which are not its fault !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2019
05:30 AM
Hi imshalla,
If most other users are getting 100% TOTAL DEAD DEAD LOCKUPs which only motherboard reset button / power button can unlock.... then yes, my issue mostly have some other additional reasons.
In my case setting BIOS to prevent C6 and setting kernel boot to idle=nowait and BIOS to typical current Idle - all did some percentage of improvements to my system stability - which I am amazed by this ANALOG BEHAVIOR! I am expecting digital behavior but not getting it. What I mean is, I expect to see a drastic effect with one particular factor e.g. C6 power state - which will freeze if enabled and completely OK if disabled. But this is not the case in my system! In my system doing that change will only change it between bad & worst - worst when C6 enabled.
The analog characteristic made me believe in power supply voltage stability - which is analog itself. Then the theory logically be that these other factors contributes to drastic CPU core power voltage fluctuations which destabilized the system - and thus eliminating each such factors slight helped my stability. This theory led me to replace my power supply unit.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-30-2019
02:51 AM
Dear All,
I am back here today to provide another update.
My system during the past 40 days or so had been 100% stable without any lockup.
It is thus conclusive that the followings are crucial solutions to my case:
- BIOS UPDATE to disallow C6 CPU Power State.
- Linux Kernel Bootup Parameter idle=nomwait = this MUST BE in every virtual machine without exception!
- Linux Kernel version other than 4.18.xx Ubuntu - this is NOT a Ryzen specific issue, happens to my Intel as well!
I had tried things like changing power supply unit, cooling fan... and found these irrelevant.
The irony now is AMD local distributor offered me a TIME LIMITED replacement within the next few days, and I am quit unsure, because their reply to my question on weather this replacement unit is one that AMD had solved the mwait & C6 lockup issue - they said they have NO IDEA, but this replace unit offered to me belongs to their NEWEST BATCH, much much newer version than my (packing box serial number was given to them for RMA before).
There are 3 possible outcome to expect when I changed it:
Optimistic Case = solved C6 & mwait lockup perfectly
Waste-Time Case = nothing changed - still exactly the same old way
Nightmare Case = opening a whole new can of worms, and bugs for me to waste time debugging!
However, before changing, I would like to TEST SKULL's program.
I searched my gmail for a zip file which I believe I had previously received. But not found. Can pse highlight to me where to download it, and some basic instructions how to compile & test them, before I replace the CPU chip with AMD distributor.
Thanks
uyuy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-04-2019
02:16 AM

I tried to run the Docker but failed to run, this was from the ZIP file which URL was posted here.
Today I exchanged the Ryzen RMA with local AMD distributor. Have not tested weather it will hang with C6 or without the idlel=nomwait boot parameters yet. Will try within several days when I got time. Will update to this forum. So far the exchanged RMA CPU booted up and running all the existing things as before RMA exchange.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2020
01:58 PM
Bit late now, but you don't have docker installed. It is telling you - "docker: not found"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2019
02:55 PM
For the record: I have been suffering from the "lock while idle" problem for a while and setting "power supply idle control" to "typical current idle" on my ASRock X470 solved it. Out of curiousity, I tried updating to the lastest BIOS (AGESA 1.0.0.6) and Linux kernel 4.19.12 and tried it without "typical current idle": it did lock up again.
My conclusion: This problem is still unsolved on the BIOS/kernel side and "typical current idle" still the only workaround with no insight or support from AMD whatsoever.
This may sound harsh, but, please, do not hesitate to correct me if I'm wrong. (I still hope I am.)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2019
06:38 AM
I agree with you.
The "Typical Current Idle" is a workaround for one form of "freeze-while-idle". This appears to be a hardware issue, related to the CPU going into a deep sleep (C6) from which it cannot be woken. Let me call that "frozen-solid".
The "Typical Current Idle" is (I believe) provided by late model AGESA -- so is (I believe) an AMD provided workaround. AMD have not cared to explain what this option actually does or what problem it works around.
In "Erratum 1109" AMD admit to a problem with MWAIT which may be the root cause for "frozen-solid", for which there is "No fix planned".
There appear to be other "lockups" where the CPU is not "frozen-solid". In particular where some threads stall or stop, but not everything.
It could be that these are symptoms of "frozen-solid" at a Core or (hardware) Thread level... perhaps the OS has a (software) thread allocated to a (hardware) Thread which has "frozen-solid" and will not wake up when kicked... perhaps it is when all (hardware) Threads are "frozen-solid" that one sees the CPU "frozen-solid"... who can tell ? In which case, perhaps a wide range of "lockups" are, indeed, related.
However, the other "lockups" could be software or other hardware. In particular, I note "lockups" for which "Typical Current Idle" does not help. Also, I note "lockups" which "idle=nomwait" does not help. These feel to me like different problems... but I have no way of knowing.
AMD could cast some light on this. But I am not holding my breath.
[FWIW, the Kernel Maintainers are also notable for their total silence; which is another disappointment.]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2019
02:37 AM
Bad News!
Seems the instability RETURNED without anything changed on hardware / software / OS!
I had in the last 3 days frozen X screens about 4 times, with mouse cursor still alive. I needed my favorite sddm restart via SSH : sudo systemctl restart sddm to get back my X screen alive.
Also there is a NEW DISCOVERY CONTRARY to the past:

https://i.ibb.co/Df1JpVr/Server-Hang-X2-Screenshot-20190128-180327.png
{kind=link}
I could X-remote via ssh to see this on a remote PC when the Ryzen X hang and quite different from all the other times before, I can see CPU12 & 13 & 14 & 15 stuck @ ZERO% and CPU 10 & 11 just occasionally bumped to few percent and Zero most of the time. I observed this for 5 mins approx.
The update of my VPN re-connect difficulties is less suspected on Ryzen related - more likely ISP network / firewall issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-04-2019
03:44 PM
Hi All,
I realized what recently caused setback to stability can be related to 2 of my several VMWARE virtual machine's kernels being updated automatically to the 4.18.0-13 & 4.18.0-14 which I had previously encountered BIG PROBLEMS, and solved after changing kernel [in the actual host machine's OS]. I am not able to change the OS kernels yet but for the time being I added idle=nomwait kernel parameters to their boot command lines and rebooted them - just for the time being. And will observe for a further period, and until I have time to change kernels.
I am not sure if this Ryzen Issue will affect Virtual Machines or not?? 
And if a virtual machine's thread hangs will the host also die??
I found today the AMD RYZEN ERRATA PDF, mentioning their various issues discussed here.
https://www.amd.com/system/files/TechDocs/55449_Fam_17h_M_00h-0Fh_Rev_Guide.pdf
Disappointing to see their table listing these bugs as NO FIX PLANNED!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2019
02:21 AM
Wondering if the AMD μProf, tool would help here ??
https://developer.amd.com/amd-uprof/
They say it can do:
- Power profiling that provides system level power, frequency and thermal characteristics in real-time.
- Real-time reporting of Power, Frequency and Thermal characteristics.
- Support Remote Profiling to perform CPU and Power profiling on a remote system
Could it be so that the remote profiling can be done, so that we can get some logs ?. But then also not sure if the system would be idle enough, with the profiler processes running, to reproduce the problem.
Don't we have some JTAG like interface to hardware debug in Ryzen CPUs ? I believe modern Intel CPUS can be hardware debugged through a USB 3 port.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2019
04:00 AM
We decided to get 3 Ryzen 2700x machines for testing at work, and we are bitterly disappointed that they randomly freezes in Linux 
The only message I get in journalctl is "rcu_sched detected stalls blablabla", and sometimes I don't get even that. I test the system by compiling QEMU with -j16 in a loop (so it has some time of load and some time of idle).
Things I've tried:
- Typical Current Idle
- idle=nomwait
- recompile kernel and add rcu_nocbs=0-15, kernel versions 4.15.0-43 and 4.20
- zenstates --disable-c6
- processor.max_cstate=3 (not even 5, just to be sure)
- set SoC at 1.1v instead of default 0.8-0.9
Configuration:
2700x
4*16gb Ram. It is rated at 3000MHz, but I set them to 2133, just to be sure (lockups occur much faster at 3000MHz, literally minutes)
ASRock B450 Pro4 at one pc and ASUS X470 Pro in two others.
Samsung 860evo 250Gb
Aerocool KCAS 650 80+ Gold PSU
GT1030
I've tried using B450 Pro4 in Windows, and it's already at 48 hours of uptime, while Linux will freeze after 1-5 hours. I'm currently trying another PSU (800w platinum), but I don't expect it to help either. I have no idea what to try next
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2019
07:51 AM
I feel for you :-(
--------------------------------------------------------------------------------------
My experience is with the earlier Ryzen 1800X. With that I tried:
- rcu_nocbs=0-15 with CONFIG_RCU_NOCB_CPU=y
- zenstates --disable-c6
- zenstates --c6-package-disable
- a PSU which guaranteed 12V at 0A
- "Typical Current Idle"
Only the last worked for me. Though with --c6-package-disable and rcu_nocbs, it froze after 11 days.
I have not tried idle=nomwait. My guess is that this is another way of avoiding going anywhere near C6.
AMD have specified that the PSU must be capable of maintaining 12V at 0A. The Aerocool KCAS 650 claims to be "Compliant with ATX12V Ver.2.4". ATX12V v2.4, section 3.2.10 seems to:
- REQUIRE +12 V2DC to operate down to 0.05A
- and RECOMMEND that it operates down to 0A
If AMD really mean 0A (and 0.05A is not good enough), then the Aerocool KCAS 650 may or may not satisfy the requirement. [But in my experience, 12V at 0A did not fix the problem.]
--------------------------------------------------------------------------------------
Since you are suffering even with "Typical Current Idle", I wonder if the problem is not the same. Also, I did not see "rcu_sched detected stalls..." and it was generally days before it froze.
In your position, I would put to one side all the C6, PSU etc. voodoo, and see whether the "rcu_sched detected stalls...", and any logging associated with that, can tell you anything more about what is going on.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2019
04:57 PM
Hi All,
I think I made my most significant discovery and conclusion so far and like to share here:
All the while I have focused limitedly on the physical Ryzen computer, which is a server running up to 8 vmware virtual machines. What I had not thought of was the virtual machines themselves!
Today I suddenly realized that even the mwait instructions running inside the virtual machines will freeze up threads, this includes ALL virtual machines! including those emulating 32 bit CPUs using my Ryzen. The only slight difference is the vmware virtualization layer seemed to mitigate the freezing effect to NOT completely lockup - that it's virtualization layer will still take away the physical CPU from the frozen threads inside the virtual machines.
This is why I had partially sticky / unresponsive characteristics and not entirely dead - I could still SSH into this physical server and do my soft reset via command sudo systemctl restart sddm on the server and get things back on track and going. My Ryzen vm server itself had it's own kernel startup parameter set to idle=nomwait already, that is why it is not too dead by itself, and I could still ssh into it!
I have still got crazy problem all these while because the virtual machines threads had gone frozen!
I had also confirmed now that my BIOS version F4e of Gigabyte GA-X470 prevented the C6 powerstate lockup, which I believe if happened to me will only be able to unfreeze by motherboard reset key. I had since BIOS update not been in such horrible bad state.
My Linux virtual machines are now added with idle=nomwait kernel parameters to boot. Stability of the overall system improved further.
However, I am not reached to bottom of all my troubles yet, because I have 3 non-Linux virtual machines which are BSDs. I am uncertain yet if h idle=nomwait kernel parameters are applicable to BSDs, I need to read documentations further.
So it explains a little about my issue of VPN re-connection difficulties - the VPN server is BSD, when it got connected, there are periodical ping every few mins to keep link alive hence prevented the mwait instruction freezing the thread in some ways.But once they got disconnected and idle the mwait instruction freezing occurred, and thus, re-connection became impossible.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2019
06:41 AM
You post game me an idea for further testing. I've been struggling with the freezes for the last several weeks. Now they do not interrupt my workflow, but I can still trigger them if I want to.
If I install 18.10, everything seem to work fine with idle=halt, but if I install VirtulBox with 18.04 and start compiling curl in a loop, the HOST will freeze after a couple of hours. Even if the host is Windows 10, I can still freeze it with 18.04 running in VirtualBox, even with idle=halt as a kernel parameter for guest.
This behavior happens on 4( ! ) different machines, including my home PC with Ryzen 1700, not 2700x as three others.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-20-2019
10:32 PM
Throwing my hat into this issue. Got a cheap refurbed HP 580-137c off of woot, so BIOS updates may not be as frequent and BIOS will definitely will have limited customizable stuff.
- Ryzen 7 1700
- Debian unstable
- kernel 4.20.10 (compiled from kernel.org)
- compiled with CONFIG_RCU_NOCB_CPU=y
- added "processor.max_cstate=5" kernel argument
- disabled c6 state with ZenStates-Linux
The last 2 (kernel argument & zenstates) I just did after dealing with random lockups every day or two while computer is mostly idle. Hopefully the zenstates thing pans out.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-01-2019
09:46 AM
Before making above changes, I could not get system to stay up for more than two days. I am 8 days in since doing the above.
Big thank you to all who contributed to this thread
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-01-2019
09:57 AM
If you don't mind, can you test your system with this script for docker? https://forum.level1techs.com/uploads/default/original/3X/e/f/ef755eb33d5979ad5704bc9146b64e526df13a...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-01-2019
10:36 AM
To do that, I need a day or 2 when company are having vacation / holiday, and I can shut off their servers. Put a spare disk inside that system then I can do it.
Or I until I setup a spare server to swap up this Ryzen system. There is already a plan to have this spare server next month or April, after a trip overseas.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-01-2019
05:09 PM
your docker script locked up my system
What did you want to look at (syslog/messages/docker logs/??)?
this is from syslog:
| Header 1 |
|---|
| Mar 1 16:43:50 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=2158 Mar 1 16:43:50 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=2159 Mar 1 16:44:54 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:44:54 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=6553 Mar 1 16:44:54 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=6554 Mar 1 16:45:57 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:45:57 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=10907 Mar 1 16:45:57 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=10907 Mar 1 16:47:00 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:47:00 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=15299 Mar 1 16:47:00 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=15300 Mar 1 16:48:03 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:48:03 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=19557 Mar 1 16:48:03 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=19557 Mar 1 16:49:06 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:49:06 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=23766 Mar 1 16:49:06 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=23766 Mar 1 16:49:53 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:49:53 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=28155 Mar 1 16:49:53 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=28155 Mar 1 16:49:53 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [atop:15084] Mar 1 16:50:21 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [atop:15084] Mar 1 16:50:49 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [atop:15084] Mar 1 16:51:12 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:51:12 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=33029 Mar 1 16:51:12 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=33029 Mar 1 16:51:13 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 23s! [kworker/4:2:30442] Mar 1 16:51:17 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [atop:15084] Mar 1 16:51:41 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 23s! [kworker/4:2:30442] Mar 1 16:51:45 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [atop:15084] Mar 1 16:52:09 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:52:09 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=37651 Mar 1 16:52:09 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=37651 Mar 1 16:52:09 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 23s! [kworker/4:2:30442] Mar 1 16:52:13 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [atop:15084] Mar 1 16:52:37 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 23s! [kworker/4:2:30442] Mar 1 16:52:41 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 23s! [atop:15084] Mar 1 16:53:05 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:53:05 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=42517 Mar 1 16:53:05 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=42517 Mar 1 16:53:05 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 22s! [kworker/4:2:30442] Mar 1 16:53:09 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 23s! [atop:15084] Mar 1 16:53:33 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 22s! [kworker/4:2:30442] Mar 1 16:53:37 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 23s! [atop:15084] Mar 1 16:54:01 kernel: watchdog: BUG: soft lockup - CPU#4 stuck for 22s! [kworker/4:2:30442] Mar 1 16:54:05 kernel: rcu: INFO: rcu_sched detected stalls on CPUs/tasks: Mar 1 16:54:05 kernel: rcu: 14-...0: (1 GPs behind) idle=f9e/1/0x4000000000000000 softirq=13830753/13830757 fqs=47508 Mar 1 16:54:05 kernel: rcu: 15-...0: (1 GPs behind) idle=ee2/1/0x4000000000000000 softirq=6372118/6372121 fqs=47508 Mar 1 16:54:05 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 23s! [atop:15084] |
Let me know if there's something specific you'd like to see...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2019
12:52 AM
Just the fact that your system froze was enough. I see a lot of people saying that some option or setting helped them, but so far the only thing that definitely helps is disabling smt. This docker just recreates the problem on any system (including windows!), And I don't believe that the problem is with docker, because native xubuntu 18.04 freezes in the exact same way.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-02-2019
12:42 PM
For my specific use case, the workaround in my previous post seem to be "good enough". I'd done two multithreaded kernel compiles with no problems and my uptime was far better than anything I had experienced prior to the workarounds.
Hopefully it is legitimately fixed at some point, though, as there is clearly an issue that needs to be fixed (not just worked around). Thanks ruspartisan !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-16-2019
10:55 AM
Just chimed in to say that there is a newer BIOS for ASUS X370-PRO Mobo users
Version 4406
2019/03/11
2019/03/11
10.24 MBytes
But then they recommend to update to AMD chipset driver 18.50.16 or later before updating BIOS.
Not really sure about how it relates to in a Linux environment.
Then, It is also interesting to note that the BIOS size has doubled, from 5.87 Mbytes in 2017 to 10.24Mbytes in 2019 !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-24-2019
12:09 PM
News on the Ryzen stability front.
I recently updated three systems in the field that were the most problematic of over a dozen systems we have deployed. See my previous posts.
In one case the system that was freezing about every two weeks I replaced the MOBO and power supply keeping the same CPU. The MOBO was a newer model with X470 chipset. I updated the BIOS and turned on "Typical Idle Current" running the same workload it has been running for months it has frozen up twice in past 6 weeks so essentially the same as before. One make one think that the particular CPU may be the issue again see my prevoius post.
In the second case was another almost identical Ryzen system at same site. It has only rarely locked up (2 times in past 6 months) I just updated the BIOS to latest and turned on Typical idle current. It has however locked up once again since this update.
In the third case of a system that would freeze up every couple of months (typical and shocking for all non-overclocked moderately loaded Ryzen systems I have experience with) I updated the BIOS and enabled modest overclocking as this has seemed to stabilize Ryzen systems (again see my prior posts) it has not locked up since I enabled this overclocking a few weeks ago but a bit too early to make conclusions.
I will also note that over the past 3 months I have 3 Ryzen systems here and have presented them with various workloads from doing nothing to CPU mining I have only had one freeze and that was one of the systems running a test where it compiled the Linux kernel using multiple threads repeatedly. So not enough data to make conclusions about workload effects but as 2 of the three systems were powered on but doing nothing most time for many months prior with no lockups it seems that the lockup problem I am noting here is not the Idle problem but something else?
All the systems I noted in this post are running at nominal CPU temperatures even when heavily loaded.
Lastly I will note that of the 3 Threadripper systems we have deployed running similar workloads none have locked up in about 30 months of operation. So something must be different about Threadripper or the VRM on typical Threadripper MOBO's.
It would be nice if someone from AMD would weigh in on this as I have seen many posts not so much here but elsewhere noting similar reports of random infrequent lockups of Ryzen systems. I assume the reason most users have not reported this is that most desktop systems have light or no load most of the time and therefore the average frequency of this problem for most is probably many months between lockup events.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-24-2019
12:28 PM
To the handful of others that have been RECENTLY posting on this thread.
It appears that most of the posts have morphed from the original Idle problem that seems solved with the "typical Idle Current" BIOS setting to the same thing I am noting of random crashes under various "server type" workloads.
I sort of think we are all seeing the same thing just with varying frequency. It sounds like some can repeat it within days not something I have achieved.
For those that can frequently repeat complete system freezes (not software crashes) I would be very curious to know if you could set modest overclocking in the BIOS (by just a few percent of rated speed) but with a constant core voltage of 1.40V this setting should ensure that the VRM stays at this constant voltage.
If done right your CPU will run warm, about 50C at idle.
But I am curious to see if this stabilizes your system under the workloads you run?