- AMD Community
- Communities
- Developers
- OpenCL
- Re: SYCL application development on Windows
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
OpenCL
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-13-2019
08:22 AM
SYCL application development on Windows
Currently all means of developing SYCL applications on Windows are either discontinued or has missing driver/runtime components.
- Codeplays ComputeCpp has prime time support for SPIR, experimental SPIR-V and has an AMDGPU back-end on the back log.
- SPIR was last supported in Radeon Software 18.2.3 (hence discontinued) which is over a year old.
- SPIR-V at the time of writing is still missing from latest Radeon Software runtimes. Ideally, current 2.0 implementation need be pushed to 2.1 which introduces SPIR-V, as is also the requirement for ComputeCpps experimental SPIR-V back-end.
- Finishing the AMDGPU back-end is up to Codeplay, but it's a workaround that should really not exist.
- HipSYCL recently moved to a Clang plugin compilation model. In order to leverage this path, ROCm need be ported to Windows.
- I got a little disconnected with triSYCL development since they started to focus on compiling with Clang. The OpenMP back-end would require OpenMP 5.0 support from either Clang or MSVC on Windows, none of which is going to happen anytime soon.
- Edit: Intels Clang fork with SYCL which is being upstreamed in a slightly non-conforming manner exposes SPIR 1.2(.1) atop an OpenCL 2.1 runtime with SPIR-V.
I understand there's a strong focus on ROCm, but the ecosystem perhaps reached the volume where the gains of porting ROCm to PAL would outweigh the costs. The relevant issue on Github was closed, the question on this forum receivies no official statement.
Edit: As a sidenote, the title might as well have been just st SYCL development, without the Windows part. On my Linux install which I rarely boot can only handle HipSYCL. Codeplay requires an extremely outdated AMDGPU-PRO which requires an older Ubuntu even, triSYCL is moving to Clang instead of baking an OpenMP 5.0 back-end (which would still require GCC to up its game concerning hooking it into the AMDGPU back-end)... so generally, this awesome Khronos GPGPU API is very hard to get working on AMD GPUs in any way.
10 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-06-2019
07:38 AM
Some time ago I bought a GPU which (at that time) was well-featured and (I believed) suitable for supporting my GPGPU interests. This was a Tonga-based AMD FirePro.
Since then, I have been continually frustrated by development tools (languages, compilers and runtimes) not working end to end in a single operating system for the particular GPU I have. At times, I have got tantalisingly close with a promising toolset but for one reason or another have not been able to get over the line with a working platform - Windows or Linux.
SYCL is the latest example that would seem to be a straightforward way to give me what I am looking and that appears to be well supported and with a clear and promising future development path.
I have not had an issue with wither OpenCL and Vulkan on my system, so why should there be one with SYCL?
Why does everything have to be such an uphill battle - is it that my current Windows/FirePro system is so unique in some way that github generic build instructions fail?
What am I doing wrong? I recently installed Golang and that was such a different experience, everything just worked. Am I just expecting too much when it comes to GPGPU? Is it too cutting edge? Should I just give up with AMD and go through the whole thing again with NVidia? Is there any combination of operating system and toolset that will give me the platform I want that works and with a GPU that I can afford?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-11-2019
08:04 PM
Thanks for the reply, Dipak.
I understand that technology is always moving and any piece of hardware or
software has only a relatively small window of application and support.
From what you say, if I update my Tonga-based FirePro to a later AMD-based
Graphics card there might be support for that in the future, at least on
Linux.
I liked the idea of SYCL being single-source compile and OpenCL being a
flexible way to control GPGPU hardware acceleration.
At least that would be more affordable that the FPGA acceleration route - I
was just looking at the equivalent route for Xilinx and Altera devices and
that came out at between 6,000 and 15,000 dollars for a PCI-e card.
What's nice about that platform for high performance is flexible pipeline
parallelism in hardware on a massive scale - is there any reference
material you could point me towards that shows how to achieve something
similar algorithmically using vectors in cascaded computations with data
parallelism?
David.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-12-2019
07:23 AM
Hi David,
It would be really helpful if you can explain a little bit more about your query. I mean, what kind of information/documents are you looking for?
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-12-2019
08:13 PM
The case I have in mind is where there are a series of calculations with
the output data of one fed into the input stage of the next. I suppose this
could be done by feeding one compute unit with the output from another
compute unit and this achieves a level of parallelism if the kernels are
launched at the same time but there is a lot of overhead. However, because
the processor elements in an FPGA can be connected output to input
spatially, it means that you effectively get multiple cascaded calculations
in the same number of clock cycles it would take for one operation. My
question was, if there is a recognised method of using indexed or offset
addressing within a GPU compute shader where a single wavefront could carry
out multiple calculations in the same way, with the buffers containing
sequential stages of result rather than just an array of inputs transformed
into an array of outputs by a single calculation per shader execution?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2019
05:01 AM
Thank you for the detailed description.
First of all, the implementation defined hardware features like compute units (CU), SIMD units, wave-fronts etc. are not directly accessible to OpenCL applications. The GPU scheduler is responsible for dynamically assigning the work to the CUs and SIMDs.
Pipeline style programming can be done using OpenCL, however it needs to be designed according to the GPU architecture. Multiple kernels can be launched with some data dependency so that they work in a pipeline manner. One kernel will produce some result that will be consumed by another kernel. The kernels can have a single or few work-groups and the work-group also can have only one or few work-items.
To achieve such inter-kernel communications between two running kernels, you need appropriate hardware/platform feature support as well as right OpenCL version. For example, "pipe object" was originally introduced in OpenCL 2.0 for this purpose only, however it was not so useful because its synchronization points were same as OpenCL buffer which does not guarantee the required memory consistency. As I know, OpenCL 2.2 has introduced a new device-side pipe storage that may be more useful in this purpose. However, currently AMD doesn't support this version. Please check the OpenCL spec to know more about the OpenCL pipe object.
Another OpenCL feature that can be used for communicating between two running kernels is fine-grained "Shared Virtual Memory (SVM)" buffer with atomics. This feature also needs OpenCL 2.0 and above. You can find more information on SVM here: Shared Virtual Memory.
Instead of many long running kernels communicating with each other, one can also use event objects to establish a chain of dependency among multiple short-lived kernels. For example, the control flow may look like below:
// main host thread
while (1)
{
data = receive_data() // waiting for data to be processed of suitable size
// create a new host thread that will establish the chain of dependency and it will wait for the result from the device; the main host thread can continue to do other work
create_thread(pipeline_thread, data, command_queue ) // if command queues are in-order then different command queue should be passed so that each pipeline chain can be executed out-of-order
do_other_work()
}
// host thread managing a pipeline chain
pipeline_thread(data, q)
{
buffer = create_buffer(size_of_data)
copy_data(q, buffer, data) // host to device
launch_kernel(q, kernel_1, data, event_0, event_1) // event_0 indicates dependent event object (NULL if no dependent event), event_1 is the returned event object
launch_kernel(q, kernel_2, data, event_1, event_2)
...
launch_kernel(q, kernel_n, data, event_n_1, event_n)
waitFor(q, event_n)
copy_data(q, data, buffer) // device to host
release_buffer(buffer)
process_at_host(data)
do_other_work()
}
The above can be done more easily by the "device-side kernel enqueue" feature (supported in OpenCL 2.0 and above). An application only needs to launch the parent kernel. Then, after processing its own computation, the parent kernel will launch one or more independent child-kernels on the same device. Similarly the child-kernels can also launch other child-kernels and so on. This way a chain of tasks can be done. Please refer the OpenCL spec for more information about the device-side kernel enqueue.
One of the advantages of this method is, the GPU scheduler is responsible for launching and executing the dependent kernels. If enough resource is available, multiple pipeline chains can be executed simultaneously and independently.
These are some feature references that you may explore more. There are other ways to achieve the same. I would suggest you to go through the OpenCL spec and see some online OpenCL examples. It will help you to make the right choice that is best suitable for your application logic and target hardware.
Sorry for this lengthy reply though. Hope it helps you.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2019
12:09 PM
Many thanks for very helpful info - looks as though OCL version 2.0+
compliance is needed for what I want to do and I'm better informed about
what hardware/software will give me that.now than when I bought my FirePro
card a few years ago. Heterogeneous computing is continuing to develop and
mature as an application area and I'm sure there will be more choice in
APIs/drivers/libraries for CPU/GPU/FPGAs in another couple of years. I'll
focus on other parts of the application first, take whatever acceleration I
can get with my current hardware and revisit options again next year.
Thanks again, Dipak.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2019
01:12 PM
@amd-dag FWIW if you're looking to program heterogenous architectures (CPU+FPGA+GPU+etc) and not just looking for GPGPU then I would suggest experimenting on any Intel integrated IGP and the CPU. With the Intel runtimes, you can access all architectures from the same runtime and have much better support. The vast majority of AMD's efforts lie in HIP and catching up to CUDA in feature support and speed. AMD dropped support for their CPU runtime a long time ago and has not reinstantiated it since (even though Ryzen CPUs are obliterating the competition), so even on the CPU side, your only choice is to install the Intel CPU runtime and use Intel-tuned kernel binaries.
All in all, if you're pursuing algorithm design for heterogenous architectures, I'd advise obtaining Intel branded FPGAs, CPUs and IGPs, especially how Intel dGPUs are not that far away, so by the time your codes are baked, you can buy one and run the very same OpenCL or SYCL code on all of the above.
If you wish to stay on SYCL and AMD, HipSYCL won't support Tonga, as ROCm is Polaris and up. ComputeCpp can run on Tonga GPUs on Windows with ancient drivers or on Linux with ancient drivers and Ubuntu 16.04.3.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2019
10:15 PM
Thanks for your input, Meteorhead. I mentioned FPGA because I think a
mixture of pipeline and data parallelism would suit my application best. It
may well be possible to do a bit of this with GPU but it would obviously be
a lot easier and more flexible and likely much faster on an FPGA fabric. I
think the situation for available FPGA boards and development software
seems to be comparable to the (GP)GPU ones in that a lot of them seem to be
primarily targeted at HPC/Data Centre applications and that only
corporations could afford - $10-15K seems to be the going rate for PCIe
plug-in boards. That's really out of the price bracket for most individual
developers. A heterogeneous approach using CPU/GPU and cheaper FPGA boards
would be a more realistic option in that case, certainly at the
experimental stage.
My current motherboard does have Intel HD Graphics 530 and this is the
first target found by a number of the Vulkan compute samples that I've
looked at - it also has an Intel Core i7-6700 processor. You mentioned
Intel runtime - perhaps this is the Intel llvm-sycl project on github? If
so, I tried to install this but got errors. Does the ComputeCPP package
work without this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-19-2019
03:47 AM
They are two different implementations with slightly different goals and characteristics. For a fairly comprehensive and recent inforgraphic, refer to this image.
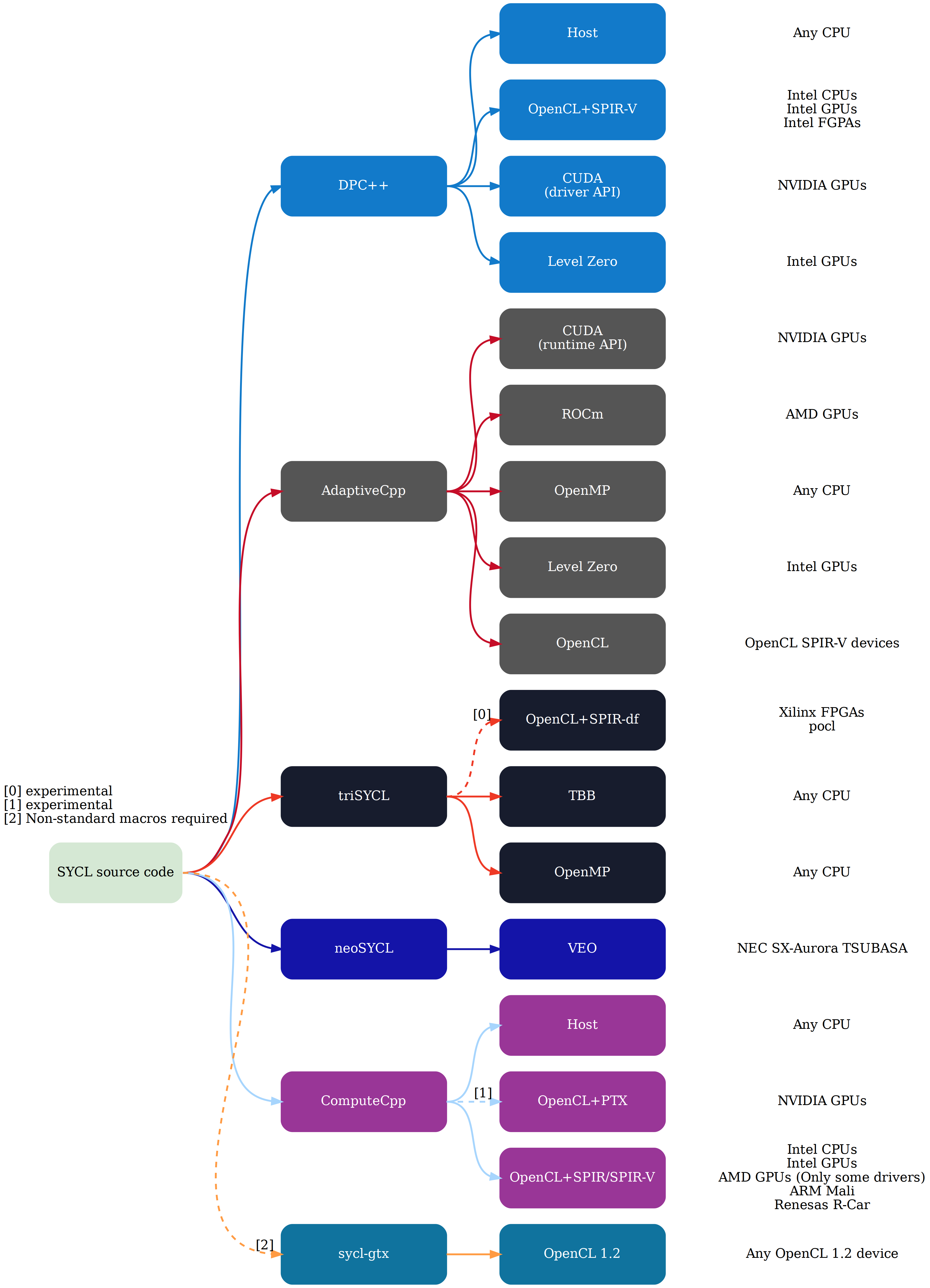{kind=link}
ComputeCpp is the only conforming SYCL 1.2.1 implementation which has a hard dependency on OpenCL. As a result, it runs fantastic on Intel OpenCL runtimes. The Intel LLVM repo you linked is a different implementation of SYCL implementing SYCL 1.2.1 (right now) but depending on OpenCL 2.1 as a back-end, because they use the easier to maintain and more powerful SPIR-V variant of SPIR, not SPIR 1.2 which OpenCL 1.2 provides. In that sense, it's a non-conforming implementation, plus you have to build it yourself. It's meant to be upstreamed to Clang, however that is a long (multi-year?) process. You can follow along the process on the Github wiki page.
At SC19 (Supercomputing conference in Denver) just last weekend many announcements were made around SYCL, so checkout news from SC19. Beside many Intel OneAPI news, Codeplay announced a lot of stuff around SYCL, even SYCL running atop CUDA. As explained by Michael in the news item, this work could slightly be paraphrased to make use of HIP. I wouldn't cound on that being an explicit goal, and even so, because HIP and ROCm are not ported to Windows, it will not be relevant to using SYCL on Windows with AMD HW. The only way that could happen anytime soon, is if an implementation were able to emit OpenCL host code and AMDGCN ISA as device code, however the amount of work required outweighs the benefit. Codeplay is closest to making that happen, but seeing these announcements portrays the direction of their efforts.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2019
10:23 PM
Have installed ComputeCpp and am now going through the code samples. May
take a bit of time to get familiar with the nested class syntax but
overall, looks to be a promising and fruitful area to focus on. There's
been a single-source C++ language for heterogeneous computing in one form
or another for a while but when I looked at AMP a few years ago but there
didn't seem to be too much benefit from that approach then over the simpler
OpenCL interface. RoCM/HPP didn't support my AMD Tonga GPU (which still
annoys me as the FirePro graphics card wasn't cheap or an old model) and I
wouldn't have wanted to go down the proprietary CUDA route, even if I had
Nvidia hardware. SYCL looks like it will generate a lot of traction as an
open-source alternative. It's neater than AMP and similar dialects, is in
tune with the development of the C++ language itself, is widely supported
and the ecosystem seems to be growing rapidly, with key libraries like
SYCL-BLAS, SYCL-DNN, SYCL-Eigen and SYCL-TensorFlow already available.
Golang is arguably a better language than C/C++ for a range of applications
but only has access to hardware acceleration via CGo, which takes away much
of the benefit and coherence of the language, debugging and development
environment. That being the case, I think I'll be sticking with SYCL for
the short, medium, or even long term and is probably a good investment for
anyone's time at the moment.