Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Archives Discussions
- AMD Community
- Communities
- Developers
- Devgurus Archives
- Archives Discussions
- Best 8GB AMD GPU for GPGPU OpenCL computational ge...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-18-2016
08:05 AM
Best 8GB AMD GPU for GPGPU OpenCL computational geometry research?
Hi,
I'm doing a GPGPU research project with OpenCL, and I need to purchase a current GPU, with the best available performance in OpenCL. It's important to get the highest OpenCL performance possible. Another requisite is having 8GB VRAM.
My research is about computational geometry. It runs fine on FP32, but what I really need is some guarantee that, if my algorithm runs slower than desired, there isn't any other AMD board in the market that would run it faster.
Looking at the possibilities, I see two options which have 8GB:
-The FirePro W8100 (peaks: 4.2TFLOPS in FP32, 2.1TFLOPS in FP64).
-The Radeon R9 390x (peaks: 5.9TFLOPS in FP32, 1/8th in FP64).
If I didn't have the 8GB requisite, I see the Radeon Fury X achieves 8.6TFLOPS peak in FP32, but with the limitation of going down from 8GB to 4GB.
I believe I must be missing something here. Does the Radeon Fire X beat all professional FirePro boards in FP32, including even the W9100 and the S9170? Of course, the question is whether I need FP64 performance or not. I had experience with NVIDIA Tesla boards years ago, which offered an FP64 performance very close to FP32, so I usually chose FP64 because you almost got it for free on such boards. But I don't really need FP64, my first requisite is very high OpenCL performance rather than having good FP64 numbers.
Thanks a lot for any ideas/suggestions,
ceses
13 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-18-2016
05:32 PM
Can you share a bit more about the nature of your project?
Is 8GB requirement a hard requirement? Could you explain the nature of your memory requirement? Do you need ECC?
Also, which OS/development tools you plan to use?
You are not missing something. Typically, if you do not need FP64, ECC or large memory capacity, you can get by using consumer version of GPU for compute and get much better bang for the buck. It is same for NVIdia products as well. You could have bought Geforce instead of Tesla and pay much less and get as good FP32 performance if FP64/ECC/large memory capacity did not matter.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2016
12:23 AM
Thanks a lot for the explanation. The 8GB requisite isn't for the
development of the algorithm I'm working on right now, but for other
project which involves very large satellite imagery, and I wished to
use the same GPU for both projects. However, considering my #1 priority in
this moment is the confidence that the OpenCL performance I'm getting is
the fastest I can expect for a single AMD device at the moment, my choice
should be the R9 Fury X and leave the 8GB project for another purchase. Is
this correct, or am I forgetting any TFLOP monster under the table?
I also looked at the R9 295x2, which many claim as still the most
TFLOP-delivering card at the moment, but looking at Luxmark I found that
single device Fiji GPUs get a higher mark than the 295x2 using the 2
devices. Also, if I'm reading the docs correctly, the 295x2 8GB is seen as
4GB by the applications, so it wouldn't give me more memory than the Fury X.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2016
03:15 AM
By the way, I forgot to reply your question about OS and tools. My system of choice is OS X but, unfortunately it doesn't have an OpenCL profiler, and I really need such a tool for this research, because I need to monitor what's happening inside the GPU and I've never been able to do this on OS X. So I'm moving to Linux for this research, both because I need an OpenCL profiler, and because I can get more TFLOPS than on OS X (even if I got a Mac Pro with 2x D700).
If the R9 Fury X has any issues on Linux, or if the AMD OpenCL profiler isn't 100% functional for this GPU on Linux, please tell me, because this is the configuration I'm considering right now.
Thanks!
cesss
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2016
04:43 AM
x2 cards: The two chips have separate memory. They can't access each others memory directly. x2 is like buying two cards but with less power consumption.
290 vs. Fury: Fury is a great card (at the moment it has the best FP32 performance and memory bandwidth too). Fury uses HBM techology so it's more power efficient and it has 2x more mem bandwith than previous cards.
Memory usage vs. math performance: If you use way more memory operations than math, memory bandwidth will become the bottleneck, and you'll end up not utilizing much of the TFlops/s of the card. On a pre-Fury card, I'd suggest to read 32bits for every 32 alu instructions. Yes, it's not that good ratio, but it's still a GPU, not a CPU. I can only quess that on the Fury this ratio became 1 DWord read : 16 alu instructions.
But on GPU it is wise to thinking of data compression: It will need less space but it will use more ALU to compress data, but that would be sleeping ALU anyways if you aren't using any compression. This compression is a trend in graphics too started long ago: The latest algorithm is Delta Color Compression. But it's always dependent of the data and precision requirement what algorithm is best for your particular data.
Streaming vs. all data in the memory:You better split up the work to 256MB (for example) blocks if you can. You can transfer a block in the same time as the GPU works on the previously transferred block. I might seem so easy to upload a very large image in one time, but GPU needs memory locality to work effective. If you rearrange the algorithm and/or the data structures to support better memory locality, you can have a sum of TByte/sec bandwidth rates from the caches of all the compute units.
What Fury model: Not the Nano. It's there for the small form factor, and it prevents overheating by slowing itself down. Choose from the 2 big models: the one with liquid cooling or the other with regular large fans.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2016
12:48 PM
Thanks a lot, realhet and bsp2020 for your explanations. I think I've almost everything clear now. My only remaining doubt is about the status of the Fury X on Linux. From what I've read googling around, there're reports of the current Linux drivers having issues with Fiji. I've read it's expected that the next Crimson 16.x Linux drivers (not released yet) together with the Linux 4.4 kernel (just released a few days ago) will bring better support for Fiji, but... is the current status bad? My only interest is OpenCL and the OpenCL profiler, so if there're issues in other areas I'm not much concerned in this moment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-19-2016
01:44 PM
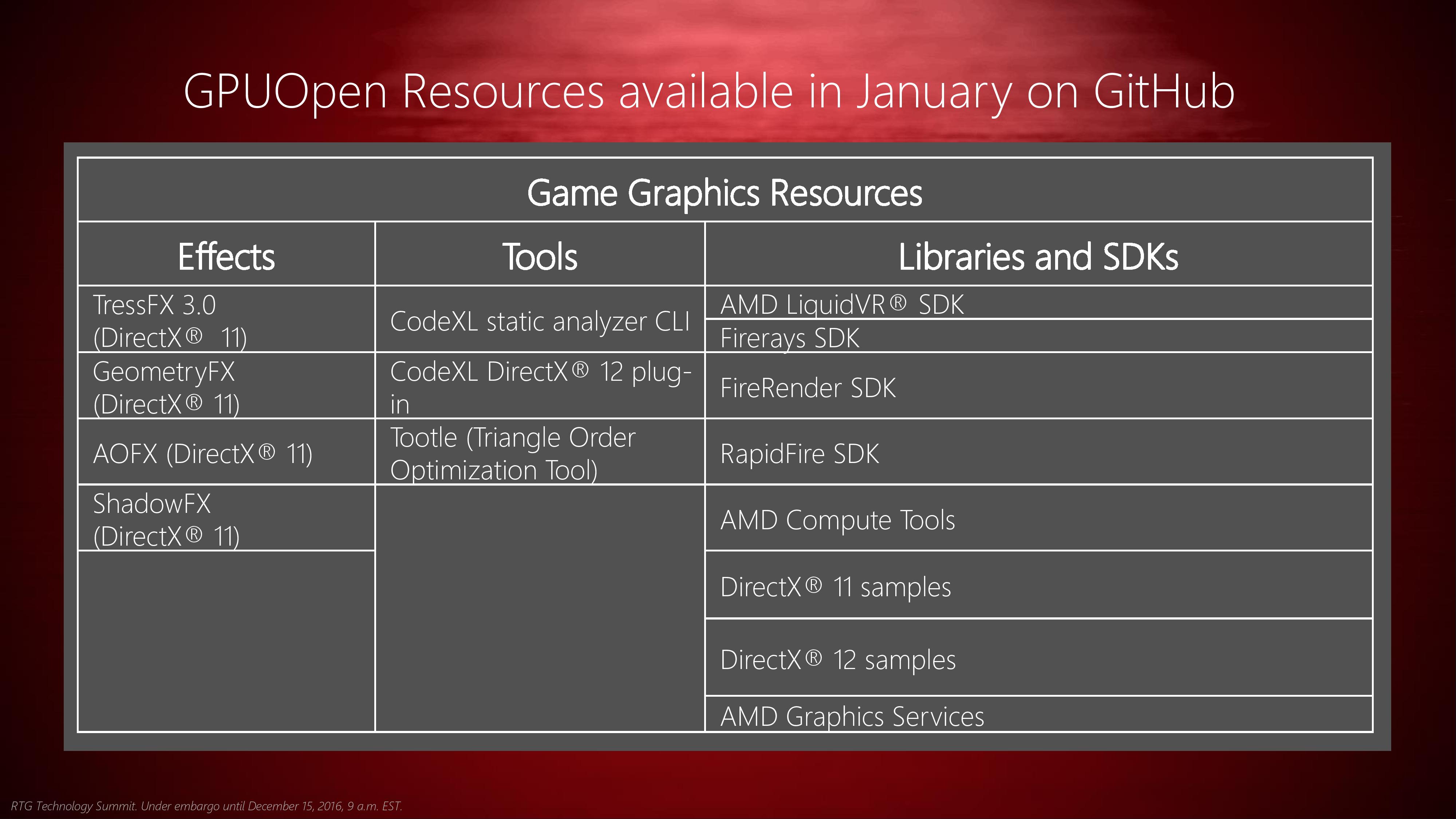
I'd wait a few days and see what is released as part of GPUOpen release this month. (http://images.anandtech.com/doci/9853/RTG_Software%20Session_FINAL-page-012.jpg)
{kind=link}
AMD Compute Tools is part of libraries that will be released this January, though I'm not sure what exactly that will include.
Do you have to use OpenCL? hcc (http://www.amd.com/Documents/HIP-Datasheet.pdf) looks very interesting to me. So, if you don't have to use OpenCL, I'd look into it as well. I believe there will be a release of hcc as part of GPUOpen. Currently it is for linux only. I do not know whether AMD plans to bring hcc to Windows/Mac. Also CodeXL does not currently work with hcc. But I think they are looking into it (CodeXL 1.9 and HSA on ubuntu 14.04 ).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2016
04:05 AM
Thanks a lot for adding this info, which I wasn't aware of. I really appreciate that such an amount of tools and libraries are being released by AMD through MIT license, which is by far the open source license that best fits in all scenarios I've worked.
I feel disappointed about the lack of an 8GB Fiji card (with the planned Fury X2 being 2x4GB, which isn't 8GB). I suppose there will be an 8GB Fiji card at some point, but I'm making the purchase in less than a month, so I don't see any other option but buying a 4GB card, given the substantial fp32 TFLOPS advantage of Fiji over anything else.
Anyway, if you've heard rumors of any 8GB Fiji card (either consumer or professional) to be released in a one/two months timeframe, please tell me (even if it's through a non-revealing line such as "squirrels enjoy the snow in February" 🙂 , as it would turn my purchase much better and would be a perfect fit with what I'd wish to have.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-26-2016
08:39 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2016
05:17 AM
With official gcn asm support! 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2016
05:57 AM
Can you please verify that these new functionality (the driver and the HCC compiler) only available for Linux?
I don't find that these things will be available if I download the new Crimson drivers for Windows. o.O
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2016
08:39 AM
AFAIK, professional compute component of GPUOpen is Linux only at the moment. I do not know whether there is any plan for Windows.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2016
02:43 AM
If the professional compute component is Linux-only, can be suppose that Fiji in general and Fury X in particular are optimally working in Linux? I've googled around, and I've read people say there're serious issues and that they're waiting for Crimson 16.x on Linux, running on the 4.4 kernel.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2016
05:13 PM
It is my understanding that what is released is for compute. It seems the graphics side is a bit behind in release and has performance issues under Linux.
I don't have Fiji and I'm not too familiar with Linux graphics driver.
If you are interested in graphics + compute, I think you need to wait till AMD release their new driver that works with AMDGPU. The current AMD Linux driver for Fiji uses the old method and can't be used on the Kernel that was just released. I have A10 7850K and, because I'm using the AMDKFD stuff, I must use open source linux driver for graphics.
