Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
OpenCL
- AMD Community
- Communities
- Developers
- OpenCL
- OpenCL Shader compiler had memory allocation probl...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2020
08:44 AM
OpenCL Shader compiler had memory allocation problem
I'm trying to compile a rather large kernel and being give the following error after 20-40 sec of kernel compile time, both in the runtime as well as under CodeXL:
Shader compiler had memory allocation problem
Error: HSAIL program is not finalized successfully.
Codegen phase failed compilation.
Error: BRIG finalization to ISA failed.
========== Build completed for 1 devices: 0 succeeded, 1 failed. ==========
I've attached a simplified version of the code, but it cannot be reproduced just with this simplification. If needed I can attach the full code. I've traced down the problem to the slide function, and think this pushes the kernel complexity over some limit, from the AMD CL compiler perspective.
What I found is that if I just remove a bit of the slide function complexity (e.g. remove most inner for or remove break), the code will compile (though still 15+ sec). How can I go about this problem ?
This is happening both under Windows as well as Linux runtime. Also for other platforms (Nvidia and Intel), code is compiling and working fine.
Thank you
9 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2020
10:07 AM
Thank you for reporting this. Please attach the complete kernel that reproduces the above issue. Also, please mention about other setup details like GPU, driver version etc.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-15-2020
01:15 AM
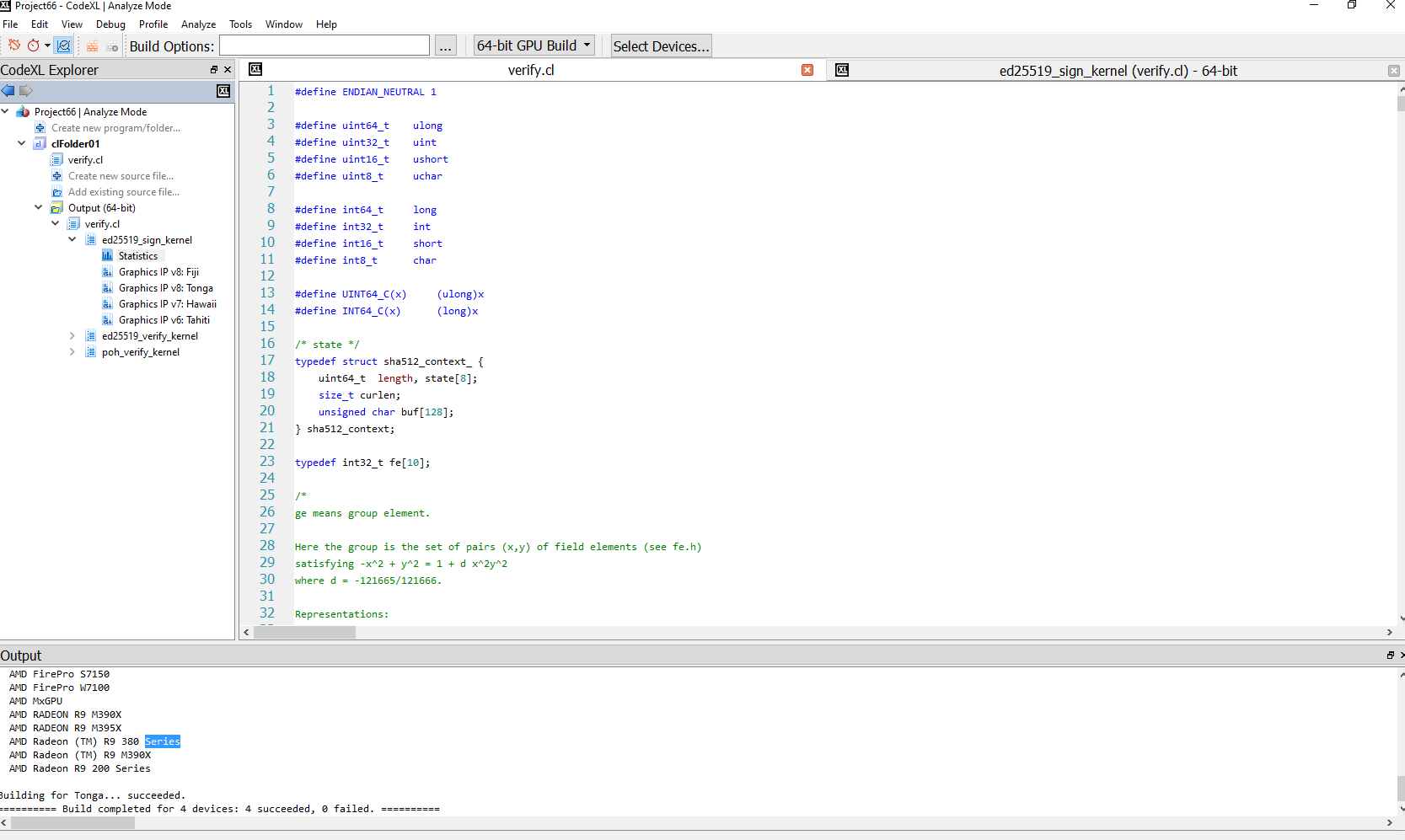
I've attached the full kernel file (verify.cl). You can easily reproduce this on most GCN architectures, both in terms of runtime and in terms of CodeXL (Analyze mode, import OpenCL source file, compile for architecture). In particular for CodeXL, I've mostly used IPv8 GPUs like Fiji/Carrizo or Vega GPUs to compile. Compilation takes around 20-40 sec, both in CodeXL and in the OpenCL runtime.
Sample output of CodeXL 2.5.67.0, Radeo Software version 19.12.2, compile failure:
1> verify for gfx900:
Compiler Log: Shader compiler had memory allocation problem
Error: HSAIL program is not finalized successfully.
Codegen phase failed compilation.
Target GPU detected:
gfx900 (Vega)
AMD Radeon Instinct MI25 MxGPU
Radeon (TM) Pro WX 9100
Radeon Instinct MI25
Radeon Pro SSG
Radeon Pro V340
Radeon Vega Frontier Edition
Radeon(TM) RX Vega
Building for gfx900... failed.
OpenCL Compile Error: clBuildProgram failed (CL_BUILD_PROGRAM_FAILURE).
I don't think the system hardware/software where the compilation takes place bares any limitation, but for reference, AMD Ryzen 3 2200G RV-B0, 12GB DDR4 RAM dual channel (VRAM 2048), AsRock AB350M +HDV, AMI 4.40, Windows 10 x64, Radeon Software 19.12.2, 2019.1204.2025.36760
As for the runtime, the following configurations have been tested:
Windows 10 x64, Hawaii GPU ---> kernel compilation failure
Windows 10 x64, Fiji GPU ---> kernel compilation failure
Windows 10 x64, OpenCL 2.1 AMD-APP (3004.7), Ryzen 3 2200G with Radeon Vega Graphics ---> kernel compilation failure
Linux x64 OpenCL 2.1 AMD-APP (2906.7), AMD Hawaii GPU ---> yields SIGSEGV
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-16-2020
01:43 AM
Thank you for sharing the above information and providing the reproducible kernel file. We will look into this and get back to you soon.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-16-2020
07:07 AM
I tried to reproduce the issue with CodeXL (for architectures like Fiji, Tonga, Hawaii, Tahiti etc.) on a test setup, but the kernel compiled fine. Please find the attached screenshot.
Setup Details: Windows 10 + Carrizo+ Adrenalin 19.12.3 (Software Version 2019.1216.1341.24649 / Driver Version
19.50.03.05-191216a-349841E) + CodeXL 2.6.361.0
On same setup, I also ran a simple OpenCL program with this kernel and it worked fine.
However, in both the cases, the compilation took several minutes (> 10 min) to finish and memory usage was very high (few GBs).
Can you please try it once with the latest driver and latest CodeXL?
Thanks.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2020
01:19 AM
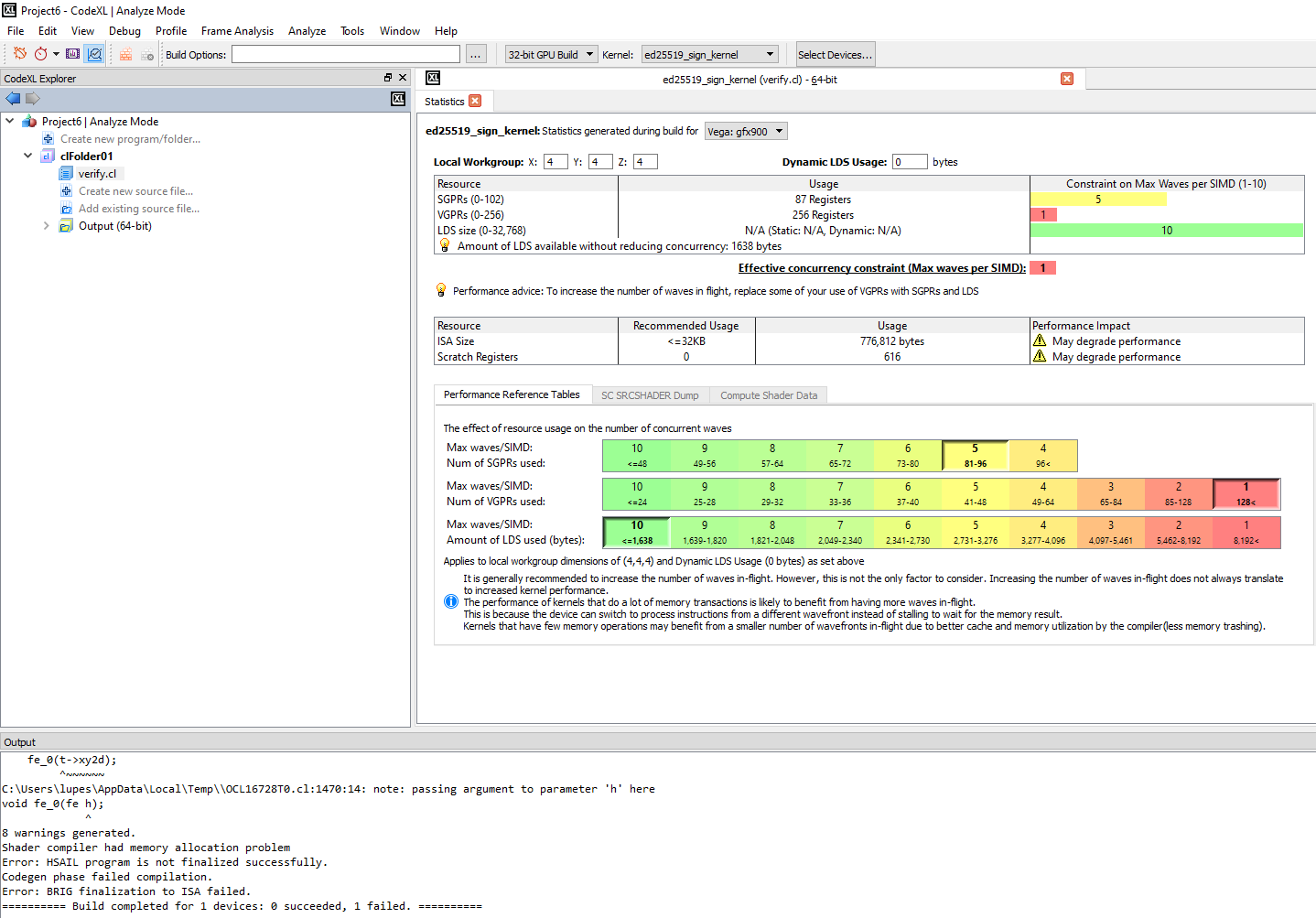
I've noticed you selected 64 bit GPU build, which is not the default variant once CodeXL starts (32 bit is). I changed the setting to 64 bit and it did compile that, but still fails the 32 bit build. Can you please run the 32 bit compile ?
As for the software I have the latest once, given AMD APU 2200G, which is 19.12.2. The version 19.12.3 is not available to me. Though the reason the build passed on your side is the 64 bit compile, I assume.
How would I know which variant the runtime is executing ? (32 bit or 64 bit)
And are there options for the compiler to spit out more info on the problem ?
In any case, even for the successful build, it takes much much longer than what other compilers are producing (NVIDIA and INTEL). What could be the cause ?
Is there any chance to be able to rewrite the code so that compilation is improved ? (successful and fast)
Thanks again for looking into this.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-17-2020
02:28 AM
Yes, I used "64bit GPU build" option which I do normally. If you build an OpenCL program as 64bit application (x64), by default it uses 64bit OpenCL runtime as well as 64bit OpenCL compiler.
By the way, I just tried 32-bit GPU build option in CodeXL and I observed similar error ( "Shader compiler had memory allocation problem") . As I said in my previous post, the memory usage was very high (few GBs) during the kernel compilation. I believe it's crossing the memory limit for 32bit compilation process and that's the reason why we are getting the memory allocation error when "32-bit GPU build" is selected.
In any case, even for the successful build, it takes much much longer than what other compilers are producing (NVIDIA and INTEL). What could be the cause ?
I will report the issue to the compiler team. Hope they can provide better insight on this.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-21-2020
06:37 AM
Update:
A bug ticket has been created against the issue and the concerned team is investigating it. Once I've any further update on this, I'll get back to you.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2020
03:07 AM
Are there any updates on the issue ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-26-2020
04:07 AM
Yes, yesterday I got a feedback from the compiler team.
After investigating the issue, they have confirmed that the 32-bit compiler tool-chain is running out of memory due to very high memory usage by the kernel. The 64-bit compiler is working fine. They don't think it's a compiler bug. They have recommended to use the 64-bit compiler for this kernel.
Thanks.
