Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Archives Discussions
- AMD Community
- Communities
- Developers
- Devgurus Archives
- Archives Discussions
- pinned buffer OpenCL vs CUDA
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-08-2014
10:12 PM
pinned buffer OpenCL vs CUDA
Hi,
I am new with OpenCL so maybe it is a stupid question.
I already know how to use pinned buffer, zero copy buffer, or device buffer in OpenCL.
I have a question that really make me confuse:
What is the different between using pinned host memory in OpenCL and pinned host memory in CUDA ??
After I do some research, I found that using pinned host memory in CUDA means you create data with cudaMalllocHost (location: pinned host memory) and send the data to the buffer on device (location: device memory).
It is explained at this link :http://devblogs.nvidia.com/parallelforall/how-optimize-data-transfers-cuda-cc/ and inside several CUDA books.
But, in OpenCL using pinned host memory means you create data with malloc (location: host memory) and send the data to the buffer on pinned host memory (location: pinned host memory).
Am I right??
And, if I create data with malloc in OpenCL, it must be moved from pageable memory to pinned memory and after that the transfer begin from pinned memory to buffer in pinned host memory is n't it??
This is according to image from link :http://devblogs.nvidia.com/parallelforall/how-optimize-data-transfers-cuda-cc/:
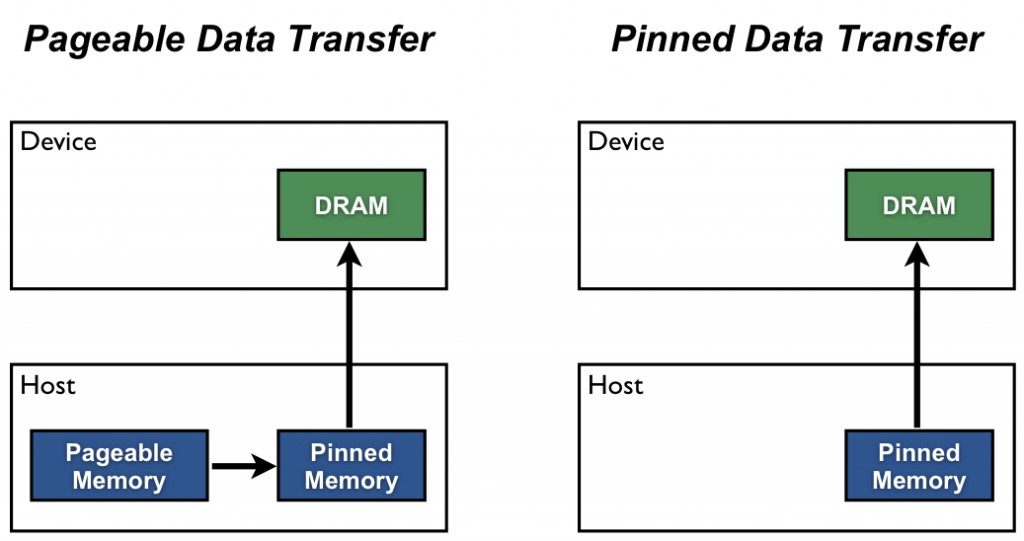
Message was edited by: Arvin Arvin
Solved! Go to Solution.
1 Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2014
11:57 AM
Thank Nou,
Just to make sure.
According to table 4.2 in AMD APP Accelerated Parallel Programming Guide, several research, and from your explanation :
There are three method of transfer in OpenCL:
1. Standard way (pageable memory ->pinned memory->device memory)
1.1 It is achieve by create data in host memory using malloc and buffer in device memory by using DEFAULT flag (none of the following flag).
Before the data is transferred then data in host memory (pageable) must be moved to temporary pinned memory and after that the data can be send to device memory.
To transfer to device memory we can use clEnqueueRead/WriteBuffer and clEnqueueMapBuffer (except using device CPU that result on zero copy)
1.2 It is achieve by create data in host memory using malloc and passing it directly to the clCreateBuffer(CL_MEM_USE_HOST_PTR ).
It will make the data in host memory (pageable) move to pinned memory and transfered into device memory (without VM) according to this link:more on memory flags | AMD Developer Forums.
To transfer to device memory we can use clEnqueueRead/WriteBuffer and clEnqueueMapBuffer (except using device CPU that result on zero copy)
2. Pinned transfer way (pinned memory->device memory)
The advantage using this transfer way is there are no cost for transfer from pageable memory to temporary pinned memory.
2.1 It is achieve by create buffer clCreateBuffer(CL_MEM_ALLOC_HOST_PTR ) in pinned host memory. According Nou, I can map buffer first (using clEnqueueMapBuffer) and fill the mapped pointer.
Because the GPU don't support VM, the process of transfer happened from pinned memory to device buffer.
The pinned buffer can be used for kernel argument but it will be slow for discrete GPU because of PCIe bandwidth limitation.
2.2 To increase performance, we can COPY the pinned mapped buffer (with ALLOC_HOST_PTR) to device buffer (with normal flag) and using the device buffer as kernel parameter by using
clEnqueueRead/WriteBuffer or clEnqueueCopyBuffer.
It still do the copy of input data into device memory but by passing device buffer as kernel argument it will be free from slow PCIe bandwidth limitation
(don't know about VM in GPU)
3. Zero Copy way (GPU read / write directly to pinned host memory)
3.1 It is achieve by create buffer clCreateBuffer(CL_MEM_ALLOC_HOST_PTR ) in pinned host memory.
According Nou, I can map buffer first (using clEnqueueMapBuffer) and fill the mapped pointer. Because the GPU support VM, there is no transfer happened (zero copy).
But, there is a drawback. If GPU read or write to pinned host memory directly for multiple times, it will make kernel execution become slow especially when GPU read from pinned host memory
(since to do a calculation, you always need more than one input data and these input data that make slow because must be read more than one time. Ex: output = input1 * input2).
The solution is using zero copy buffer just for output buffer only (GPU must write kernel only ONCE) and the input buffer will be transferred in standard way (1) or pinned transfer way (2).
Am I right (especially for bold sentences)??
You can copy my explanation and edited again if there are mistakes.
8 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2014
02:55 AM
CL_MEM_ALLOC_HOST_PTR should create pinned memory buffer. if you map this buffer it will return pointer to this pinned memory.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2014
07:39 AM
Thanks for reply, Nou.
I already know how to use pinned memory.
What I really want to know is the concept of pinned memory in OpenCL (it is different with CUDA).
Why it is different ?
In CUDA using pinned memory means you create memory allocation (using cudaMalllocHost) in pinned memory and copy the data to device GPU
(using malloc in CUDA means two way copy from pageable memory ->pinned memory->device) but
in OpenCL to use pinned memory, you create memory allocation (using malloc) in host memory (pageable memory) and copy the data to pinned host memory and accessed by device GPU.
The bold sentence is something that I wanna to ask.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2014
12:19 PM
when you use CL_MEM_ALLOC_HOST_PTR you don't use malloc. OpenCL will allocate pinned memory for you. to retrieve pointer to this memory you use clEnqueueMapBuffer(). in other work clCreateBuffer(CL_MEM_ALLOC_HOST_PTR)+clEnqueueMapBuffer()==cudaMallocHost(). the pointer that you can pass into clCreateBuffer() is with CL_MEM_ALLOC_HOST_PTR flag used for first time initialization and indeed there is a copy. but it never touched again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-10-2014
05:47 PM
Thanks for reply Nou.
You say that using CL_MEM_ALLOC_HOST_PTR means don't use malloc but in my code I still declare malloc (see in bold word) in host memory when I use pinned memory.
Or my code is wrong??
Here is my code :
//Matrix for input and output
float * matrixA = (float *) malloc(size*size*sizeof(float));
float * matrixB = (float *) malloc(size*size*sizeof(float));
float *matrixC = (float *) malloc(size*size*sizeof(float));
//Fill matrix
fillMatrix(matrixA,size, user_size);
fillMatrix(matrixB,size, user_size);
//print input for matrix A and B
printMatrix(matrixA, size*size, size);
printMatrix(matrixB, size*size, size);
// Allocate Device Memory For Input And Output
d_A = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_ALLOC_HOST_PTR, sizeof(cl_float)*size*size, 0, &err);
d_B = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_ALLOC_HOST_PTR, sizeof(cl_float)*size*size, 0, &err);
d_C = clCreateBuffer(context, CL_MEM_WRITE_ONLY | CL_MEM_ALLOC_HOST_PTR , sizeof(cl_float)*size*size, 0, &err);
void* mapPtrA = (float*)clEnqueueMapBuffer( queue, d_A, CL_TRUE, CL_MAP_WRITE, 0, sizeof(cl_float)*size*size, 0, NULL, NULL, NULL);
void* mapPtrB = (float*)clEnqueueMapBuffer( queue, d_B, CL_TRUE, CL_MAP_WRITE, 0, sizeof(cl_float)*size*size, 0, NULL, NULL, NULL);
memcpy(mapPtrA, matrixA, sizeof(cl_float)*size*size);
memcpy(mapPtrB, matrixB, sizeof(cl_float)*size*size);
clEnqueueUnmapMemObject(queue, d_A, mapPtrA, 0, NULL, NULL);
clEnqueueUnmapMemObject(queue, d_B, mapPtrB, 0, NULL, NULL);
//this function call kernel
MatrixMul(d_A, d_B, d_C, size);
void* mapPtrC = (float*)clEnqueueMapBuffer( queue, d_C, CL_TRUE, CL_MAP_READ, 0, sizeof(cl_float)*size*size, 0, NULL, NULL, NULL);
memcpy(matrixC, mapPtrC, sizeof(cl_float)*size*size);
clEnqueueUnmapMemObject(queue, d_C, mapPtrC, 0, NULL, NULL);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2014
02:27 AM
if you want get rid of memcpy(mapPtrA, matrixA, sizeof(cl_float)*size*size); them map buffer first and then call fillMatrix() on that mapped pointer. also for better performance pass blocking mapping only in last command as with in-order queue it is guaranteed that all previous task are completed. you can also consider change CL_MAP_WRITE to CL_MAP_WRITE_INVALIDATE_REGION if you rewrite whole mapped region.
you need two buffers. one pinned buffer and second device buffer. you create pinned buffer with CL_MEM_ALLOC_HOST_PTR and device with normal CL_MEM_READ/WRITE flags. then you map pinned buffer and after this you use this pointer in clEnqueueRead/WriteBuffer() as ptr parameter. never use pinned buffer as kernel parameter or as target of clEnqueueRead/WriteBuffer() operation. it will cause that this buffer will be copied to device memory. look into BufferBandwirh example from SDK what he does with -pcie parameter.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-11-2014
11:57 AM
Thank Nou,
Just to make sure.
According to table 4.2 in AMD APP Accelerated Parallel Programming Guide, several research, and from your explanation :
There are three method of transfer in OpenCL:
1. Standard way (pageable memory ->pinned memory->device memory)
1.1 It is achieve by create data in host memory using malloc and buffer in device memory by using DEFAULT flag (none of the following flag).
Before the data is transferred then data in host memory (pageable) must be moved to temporary pinned memory and after that the data can be send to device memory.
To transfer to device memory we can use clEnqueueRead/WriteBuffer and clEnqueueMapBuffer (except using device CPU that result on zero copy)
1.2 It is achieve by create data in host memory using malloc and passing it directly to the clCreateBuffer(CL_MEM_USE_HOST_PTR ).
It will make the data in host memory (pageable) move to pinned memory and transfered into device memory (without VM) according to this link:more on memory flags | AMD Developer Forums.
To transfer to device memory we can use clEnqueueRead/WriteBuffer and clEnqueueMapBuffer (except using device CPU that result on zero copy)
2. Pinned transfer way (pinned memory->device memory)
The advantage using this transfer way is there are no cost for transfer from pageable memory to temporary pinned memory.
2.1 It is achieve by create buffer clCreateBuffer(CL_MEM_ALLOC_HOST_PTR ) in pinned host memory. According Nou, I can map buffer first (using clEnqueueMapBuffer) and fill the mapped pointer.
Because the GPU don't support VM, the process of transfer happened from pinned memory to device buffer.
The pinned buffer can be used for kernel argument but it will be slow for discrete GPU because of PCIe bandwidth limitation.
2.2 To increase performance, we can COPY the pinned mapped buffer (with ALLOC_HOST_PTR) to device buffer (with normal flag) and using the device buffer as kernel parameter by using
clEnqueueRead/WriteBuffer or clEnqueueCopyBuffer.
It still do the copy of input data into device memory but by passing device buffer as kernel argument it will be free from slow PCIe bandwidth limitation
(don't know about VM in GPU)
3. Zero Copy way (GPU read / write directly to pinned host memory)
3.1 It is achieve by create buffer clCreateBuffer(CL_MEM_ALLOC_HOST_PTR ) in pinned host memory.
According Nou, I can map buffer first (using clEnqueueMapBuffer) and fill the mapped pointer. Because the GPU support VM, there is no transfer happened (zero copy).
But, there is a drawback. If GPU read or write to pinned host memory directly for multiple times, it will make kernel execution become slow especially when GPU read from pinned host memory
(since to do a calculation, you always need more than one input data and these input data that make slow because must be read more than one time. Ex: output = input1 * input2).
The solution is using zero copy buffer just for output buffer only (GPU must write kernel only ONCE) and the input buffer will be transferred in standard way (1) or pinned transfer way (2).
Am I right (especially for bold sentences)??
You can copy my explanation and edited again if there are mistakes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-13-2014
09:24 AM
Are my explanation about data transfer in OpenCL is true?? Just want to clarify.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-13-2014
02:26 PM
yes
