Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Archives Discussions
- AMD Community
- Communities
- Developers
- Devgurus Archives
- Archives Discussions
- NV_depth_buffer_float (partial) support possible?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-26-2013
03:49 AM
NV_depth_buffer_float (partial) support possible?
A bit of the background: the symmetric normalized device coordinates used by OpenGL prevent us from effectively using the reversely mapped floating point depth buffer (with far/near swapped), which tremendously improves the depth buffer precision by utilizing the exponent of the floating point depth values around 0. Unlike Direct3D, which has z in clip space in 0..1 range, in OpenGL it gets remapped from -1..1 by 0.5*zc+0.5. Unfortunately that addition of 0.5 completely destroys any extra precision around 0 gained by the reverse mapping of the depth range.
On Nvidia we can use NV_depth_buffer_float extension and DepthRangedNV() to effectively turn off that additive term and get the full precision as achievable with Direct3D with the reversed floating point buffer. Here are the (measured) depth buffer resolutions achieved:
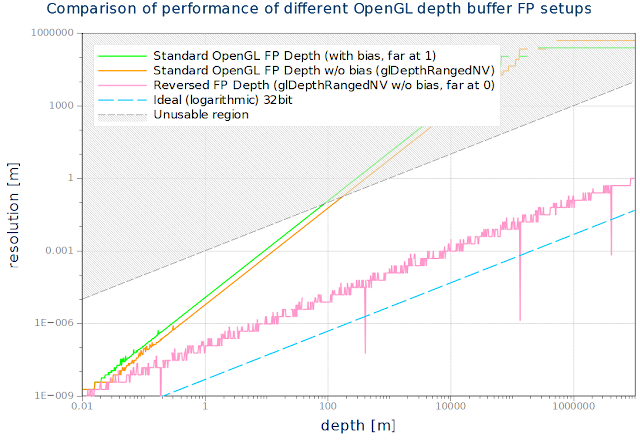
Full description can be found at Maximizing Depth Buffer Range and Precision
The bias and scaling is removed by calling glDepthRangedNV(-1, 1)
Unfortunately we can't use it on AMD, even though it could be possible in theory since it operates that way in Direct3D (without the remapping bias). We have to resort to the logarithmic depth buffer which has all the precision but disables z optimizations and that's increasingly becoming a performance problem.
So my question is - would it be possible to support the direct (D3D-like) mapping between the normalized device coordinates and the depth buffer values, removing the bias? The written depth values would be still in the 0..1 range, since I've been told that AMD hardware doesn't support writing arbitrary floating point values into the (floating point) depth buffer.
Solved! Go to Solution.
1 Solution
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-28-2013
02:50 PM
We're working on supporting the Nvidia extension now.
2 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-08-2013
01:02 PM
Verified that it works on AMD hardware by stepping into the disassembly of glDepthRange and skipping the clamping instructions to allow setting glDepthRange(-1, 1). With that the reverse FP depth buffer works with full precision as shown in the graph above.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-28-2013
02:50 PM
We're working on supporting the Nvidia extension now.
