Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Archives Discussions
- AMD Community
- Communities
- Developers
- Devgurus Archives
- Archives Discussions
- Multiple GPUs and concurrent kernel execution
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2012
05:33 AM
Multiple GPUs and concurrent kernel execution
Hi,
I'm trying to distribute work to two different GPUs efficiently by using dynamic scheduling.
My first attempt is working, but with one of the GPUs idling at one point for no apparent reason.
The basic scheduling algorithm is as follows:
Main func:
Loop through GPUs (loop control i)
lock work queue
pop item off work queue
unlock work queue
set work item's target device to i
call enqueuework function (work item)
Wait for queue to become empty
WaitForEvents(wait on all reads to complete)
EnqueueWork function (work item):
create required buffers
enqueueWrite on buffers using writeQueue
enqueueMarker on writeQueue
flush write queue
create and enqueue kernels (depends on above writeQueue marker) on execQueue
set callback on kernel completion to RunComplete function
flush exec queue
enqueueRead on readQueue (depends on kernel completion)
set callback on read complete to ReadComplete function
flush read queue
RunComplete function:
gets an item from the work queue and calls the EnqueueWork function
ReadComplete function:
Creates a thread to write the results to file
Note: All OpenCL calls are asynchronous and each device has its own set of queues.
The picture attached is the execution profile. As you can see from the image, the Cayman device isn't doing anything for ~3s, yet the buffers were written and the kernel was enqueued at the expected time. It only started when the Tahiti device finished its kernel, yet the inverse doesn't apply (Tahiti starts new kernels while Cayman is still running). Any ideas as to why this is?
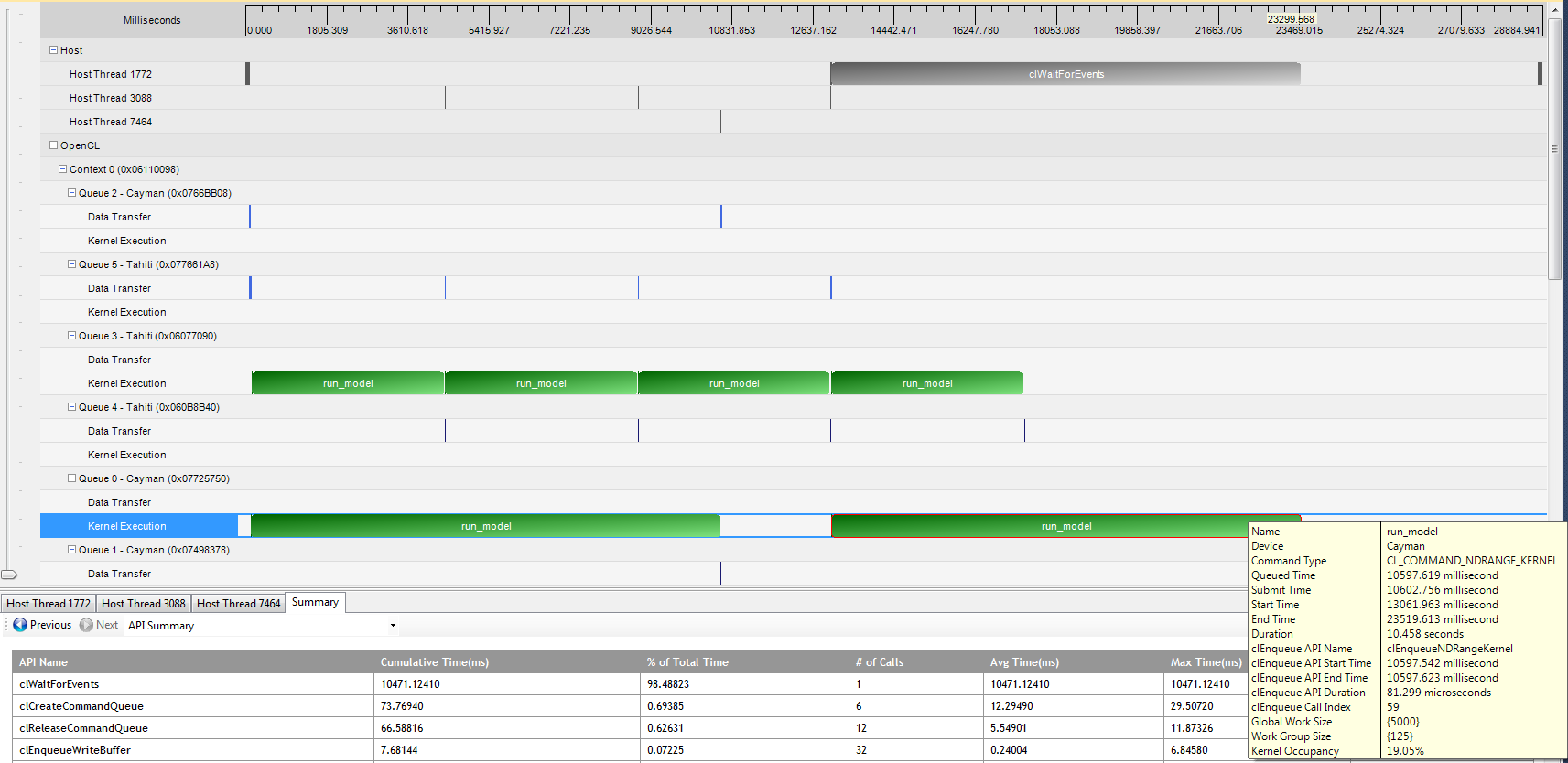{kind=link}
10 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-15-2012
09:31 PM
Hi uvedale,
From the image, queue2 and queue5 do data transfer, queue0 and queue3 do kernel execution. So I think maybe you have made a mistake in your program.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-16-2012
10:48 AM
I don't see a problem with that?
I have 6 queues in total, 3 for each device (execution queue, read queue, and write queue).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-16-2012
08:55 PM
Hi uvedale,
The threads in host are concurrent. In your image, thread 1772 is waiting for thread 3088. So Cayman doesn't do anything for 3s. First, thread1772 holds cpu resource, and Cayman starts to work. Sencond, thread3088 holds cpu, and tahiti starts to work. Because the gpus are parallel, there is nothing wrong.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-22-2012
10:41 AM
Hi Wenju,
Thanks for your input. I am however unconvinced that the problem is being caused by host thread blocking.
The host threads don't do all that much, they just schedule the next batch once a batch completes. This shouldn't take anywhere near 3 seconds to complete. Furthermore, I'm using a quad core CPU, so threads should execute in parallel (time-slicing on a single core CPU should even be adequate).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-23-2012
02:43 AM
Yep! In theory, the kernel should be executed immediately after the data transfer. And maybe it's the events in your code caused this result. Just speculating. You can change executing order, Cayman kernel executes first, and then Tahiti.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-23-2012
03:52 AM
try remove some synhronization between queues and reprofile it. maybe you will be able to determine if there isn't some blocking event.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-24-2012
10:22 AM
I'm not having much luck.
I've tried all sorts of things, such as:
- Dedicating a thread to each device for scheduling
- Use of blocking instead of event dependencies (each device on own thread, so doesn't slow it down)
- Giving each device its own context. I thought this would definitely resolve it, but alas not.
The kernels are scheduled at the right time, but sometimes they just sit in the queue until the other device has finished the kernels it is busy with. I have noticed that its always only one of the devices affected. So one device just goes for it, while the other only runs in parallel with the first device on occasion.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2012
12:58 AM
Can you offer the session files? Maybe it will be helpful.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2012
04:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-25-2012
10:09 PM
It's really hard to say. But I really think it's your program caused such kind of result. In your program, you invoked clRetainMemObject() so many times. I'm not sure whether it will have an effect on the result. Besides, you should be careful with the events. And I think you can just use one device, if the kernel executions are not continuous, so I think it's your program. But if the kernel executions are continuous, we can not say it's not the program caused such kind of result.
