Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Archives Discussions
- AMD Community
- Communities
- Developers
- Devgurus Archives
- Archives Discussions
- OpenCL Multi GPUs
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2017
06:40 AM
OpenCL Multi GPUs
Dears,
I'm looking for en example for multi gpu handling, I see SimpleMultiDevice example showing how to create multiple command queues on single context and where the input data is split into two halves with each half executed on a different GPU.
In my case I'm looking for an example of having where there are the two different programs which each one has its own kernels and the job is plit for two GPUs. The first program processes input Data and its executed on one GPU. Afterwads 1st GPU sends data to the second GPU. Here I await the output data for rendering.
Is there any code pattern demosntrating this desing?
How to modify "SimpleMultiDevice" to have tasks parallel processed?
Thank you.
3 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2017
11:59 AM
Isn't this related to pipelining ? It could need double buffering. y=sqrt((x+1)*5)
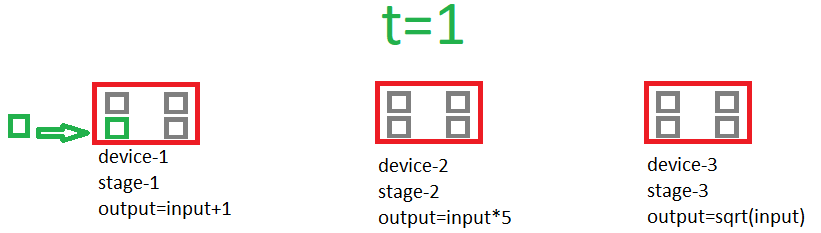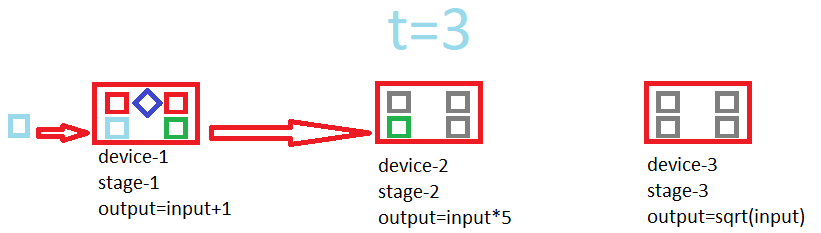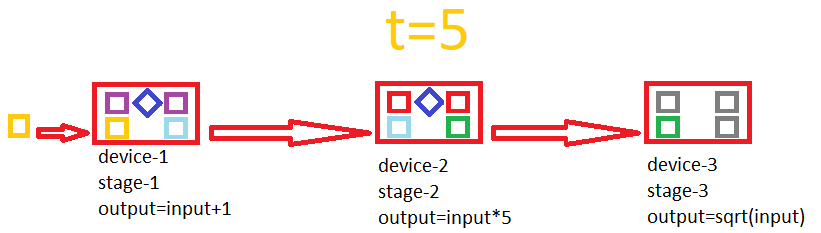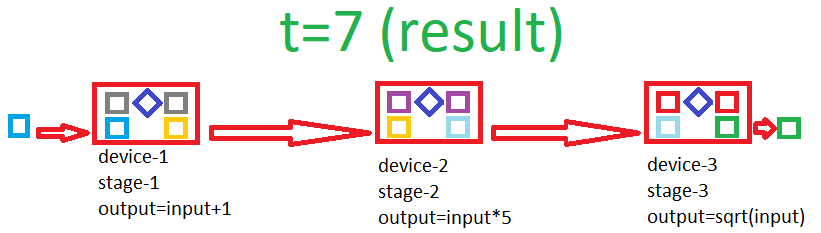
Switch upper buffers with their bottom neighbors(clones) (maybe with simple pointer magic). When switching is complete, copy data between bottom buffers(includes input/output at each end) and compute everything on upper buffers, all at the same time. Then repeat until result is popped at the far end. This could overlap read-compute or write-compute or even all of them in timeline(idk if a card can do this %100 efficiently, perfectly hiding r/w between a compute of equal latency but I experienced(with friends at forums) that R9-380 series can do this more efficient than other series).
I'm not talking in the name of AMD. If there is an error in this logic, I don't have responsibility  . Just being %80 geek, %20 fanboy.
. Just being %80 geek, %20 fanboy.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2017
12:57 PM
hmm I wanna achive running 2 algoritms in "pipeline" : first algo1 run on device1 (GPU1) and second algo2 run on device2 (GPU2)... data output of algo1 is consumed by algo2.
Since I'm not expert on OpenCL I'm not familiar with the terms "upper buffers and bottom neighbors (clones )" - can you point me to some relvent info?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2017
01:45 PM
Normally you can serially do this:
enqueueWriteBuffer() on GPU1 buffer
enqueueNDRangeKernel(kernel1) on GPU1
enqueueReadBuffer() on GPU1 buffer so result1 is now back in RAM
renqueueWriteBuffer() on GPU2 buffer so result1 is now at GPU2 as input of kernel2
enqueueNDRangeKernel(kernel2) on GPU2
enqueueReadBuffer() on GPU2 buffer so result2 is now in RAM
and run multiple instances of this software to crunch multiple independent data-inputs then drivers should do the necessary overlapping of buffer copies and kernel computes. For example, you should be able to process multiple image folders using a different instance of software for each folder, for an image processing. But, using single software instance and pipelining, you use less number of contexts per device and have explicit control over timings. Some pro cards may even shorten the way between two GPUs as in OpenCL - GPU to GPU transfer
In a pipeline, you can duplicate input and output buffers so they can be used for two things at the same time: copying and computing.
